大模型训推系统优化研究小组
团队成员
重要成果简介
南京大学 NASA 课题组携手鹏城实验室、华为技术有限公司等知名单位开展合作,共同针对大模型训练与推理性能、功耗等关键课题展开了全面深入的研究探索。其研究成果不仅在计算机体系结构领域的顶级会议上发表,更是成功在相关企业中实现了落地部署,为推动技术从理论走向实践做出了积极贡献。以下是部分代表性成果展示:
代表性成果1:面向Ascend架构的AI算子性能建模与优化技术
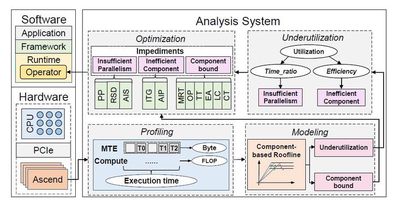
本研究针对华为Ascend NPU架构,提出了一种基于组件的Roofline模型,用于分析和优化AI算子性能。Ascend架构作为专用AI加速器,具有独特的计算单元和内存传输设计,但其复杂性给用户的性能优化带来挑战。传统Roofline模型在Ascend上存在可视化复杂和性能评估不准确的问题。
为此,本研究引入了组件抽象概念,将算子性能瓶颈归因于组件bound或利用率不足。通过改进的组件Roofline模型,研究者们能够识别瓶颈组件并进行针对性优化。该研究详细介绍了三个实际算子优化案例,包括Add_ReLU、Depthwise和AvgPool算子,展示了如何结合改进的Roofline分析识别瓶颈并优化算子,总结了常见的算子瓶颈和优化策略。
实验中,研究者对11个真实深度学习训练和推理任务中的模型进行了优化,覆盖了视觉、自然语言处理、推荐系统和大型语言模型等领域。优化结果表明,计算时间加速比从1.08倍到2.70倍不等,整体加速比在1.07倍到2.15倍之间。此外,还有41个优化后的算子被集成到Ascend算子库中。这些成果不仅提升了模型性能,也为未来AI专用架构的设计提供了有价值的见解。
相关论文:
Yuhang Zhou, Zhibin Wang, Guyue Liu, Shipeng Li, Xi Lin, Zibo Wang, Yongzhong Wang, Fuchun Wei, Jingyi Zhang, Zhiheng Hu, Yanlin Liu, Chunsheng Li, Ziyang Zhang, Yaoyuan Wang, Bin Zhou, Wanchun Dou, Guihai Chen, and Chen Tian. Squeezing Operator Performance Potential for the Ascend Architecture, in ASPLOS 2025.
代表性成果2:模型训练过程中的细粒度能耗优化工作

目前大模型训练所用的卡数越来越多,能耗开销越来越高,对模型的训练过程进行能耗的优化已成为一个重要议题。本研究利用了华为昇腾NPU提供的毫秒级生效的调频能力对模型的训练过程进行细粒度的能耗优化。毫秒级调频算子带来了更多能耗优化机会的同时,也带来了爆炸性的调频策略搜索空间,给能耗优化工作带来了挑战。
为了解决该挑战,实现以较低的性能损失代价达到较高的能耗优化,我们对能耗调优的端到端流程进行了优化。具体来说,首先我们发现算子运行消耗的 Cycle 数目与 AICore 的频率之间呈多段线性函数关系,且随着频率的升高,线性函数的斜率逐渐升高。即算子消耗的 Cycle 数目与 AICore 频率之间的关系为下凸函数。据此我们建立了准确的算子性能模型,模型在超过30000个数据点上预测平均误差仅 1.96%。其次,硬件的功耗由动态功耗和静态功耗构成,其中静态功耗由亚阈值漏电电流和栅极氧化物电流构成,其中亚阈值漏电电流和温度呈线性相关。我们的工作在功耗建模中考虑了温度相关项,优化了功耗建模的精确性,模型在多个常用负载上预测平均误差仅 4.62%。最后,在生成调频策略时,我们通过算子分类、预处理和基于遗传算法的搜索,有效地缩小了搜索空间,加快了策略优化。我们以 2% 为性能损失目标时,以平均 1.59% 的性能损失换得了 15.27% 的 AICore 能耗下降。
相关论文:
Zibo Wang, Yijia Zhang, Fuchun Wei, Bingqiang Wang, Yanlin Liu, Zhiheng Hu, Jingyi Zhang, Xiaoxin Xu, Jian He, Xiaoliang Wang, Wanchun Dou, Guihai Chen, and Chen Tian. Using Analytical Performance/Power Model and Fine-Grained DVFS to Enhance AI Accelerator Energy Efficiency, in ASPLOS 2025.