大模型软件与系统研究小组
团队成员
重要成果简介
南京大学大模型软件与系统研究小组(DeepEngine)围绕基于大模型的系统构建、规模化训练/推理部署以及大模型应用开展研究,为大模型的高效训练、部署、以及领域知识融入等关键挑战开展研究;在大模型应用方面重点关注如自动定理证明(Automated Theorem Proving, ATP)等重推理(reasoning)任务的研究,有着深厚的积累。在本科教育方面,开设大模型开发课程,培养学生“从零到一手搓大模型”的能力。小组代表性成果如下:
代表性成果1:面向大语言模型的领域知识模块可组装融合推理(MeteoRA)
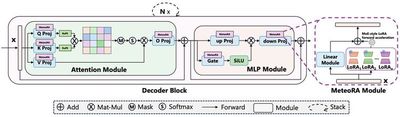
本研究提出了一种创新的MoE-style LoRA组装框架MeteoRA,通过模块化设计实现大语言模型(LLM)对多领域知识的高效融合与动态适配。框架将LLM视为主机平台,支持即插即用第三方知识模块(LoRA适配器),仅需通过少量样本微调门控网络,即可使LLM根据输入内容自感知切换适配的知识模块,实现"安装驱动即可融合知识"的灵活扩展。在28个LoRA模块融合的场景中,MeteoRA无需人工指定激活LoRA模块,可自动选择合适的模块用于推理。结合MeteoRA可使LLM推理准确率显著优于现有方法。针对MoE推理效率问题,该研究设计了基于PyTorch和Triton的两级优化算子,可将28-LoRA的MoE推理时延压缩至传统方法的1/5。特别地,在模拟复杂考试场景的N-混合任务生成中(LLM一次性依次作答N道题,每题需激活对应的知识模块),本方法通过2-shot提示模板实现逐题模块切换的状态下单次推理完成全流程。相比基线方法在答题数量与正确率上分别提升35%和27%,展现了工业级多任务场景的强适配能力。
相关论文


代表性成果2:基于图灵机机理的大语言模型计算推理执行框架
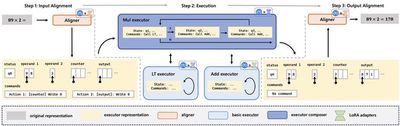
为了解决这个问题,本研究提出了一种面向LLM的可组装算术执行框架 (CAEF),使 LLM 能够通过模仿图灵机的方式来执行算术,从而理解计算逻辑。此外,CAEF具有高度的可扩展性,允许组合已经学习到的运算符,以降低复杂运算符的学习难度。评估表明,LlaMA 3.1-8B 模型配合CAEF可在 7 种经典数学算术运算的测试中实现了近乎 100% 的准确率,且能够支撑100 位操作数的计算,而同等难度下, GPT-4o 在一些算术问题测试中无法给出正确的计算结果。
相关论文
代表性成果3:南京大学选修课-大语言模型应用开发

本课程为南京大学计算机学院本科选修课,于2024年秋季学期首次开课,讲师为徐经纬,助教为黄云鹏和狄农雨。该课程以Transformer-based Causal LM为学习对象,基于PyTorch和Huggingface的Transformers框架从零开始构建可加载开源LlaMA模型的代码项目。在此课程中,将了解大语言模型最新的实现细节,如RoPE、RMSNorm及其变体、Sparse-MoE、各类Attention实现(包括FlashAttention系列)以及Megatron并行框架中Tensor Parallelism、Pipeline Parallelism、Context Parallelism和Sequence Parallelism的核心思路。


