多模态大模型研究小组
团队成员
重要成果简介
南京大学与上海人工智能实验室等其他单位,共同研发了系列视频大模型、多模态大模型,在以视觉为中心的多模态理解任务上取得了世界领先性能。代表性成果如下:
代表性成果1:书生多模态大模型-InternVL系列
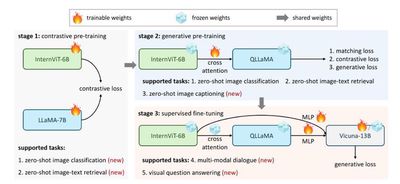
大型语言模型 (LLM) 的迅猛增长为多模态 AGI 系统开辟了无数可能性。然而,视觉和视觉语言基础模型(也是多模态 AGI 的关键要素)的进步却未能跟上 LLM 的步伐。在这项工作中,我们设计了一个大型视觉语言基础模型 (InternVL),该模型将视觉基础模型扩展到 60 亿个参数,并逐步将其与 LLM 对齐,使用来自各种来源的网络规模图像文本数据。该模型可广泛应用于 32 个通用视觉语言基准测试,并在这些基准测试中取得最佳性能,包括视觉感知任务(例如图像级或像素级识别)、视觉语言任务(例如零样本图像/视频分类、零样本图像/视频文本检索),并与 LLM 链接以创建多模态对话系统。它具有强大的视觉功能,可以成为 ViT-22B 的良好替代品。
相关论文:
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, Jifeng Dai, InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, in CVPR 2024.
代表性成果2:视频基础表征模型-VideoMAE系列
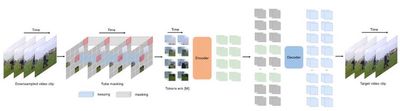
本成果提出了视频掩码自编码器 VideoMAE v1 & v2,成功训练出了首个十亿参数量的视频 Transformer 模型,突破了视频自监督表征学习的性能瓶颈。VideoMAE 系列工作引用超过了 1500 次,并且成为视频自监督学习领域的基准方法,被牛津大学、微软、谷歌、Meta 等单位进行了跟踪拓展研究,成为被开源社区 Hugging Face 收录的首个视频 Transformer 模型,全球调用下载量超过 320 万次,位列 Hugging Face 视频识别模型下载量榜首。
相关论文:
Zhan Tong, Yibing Song, Jue Wang, Limin Wang, VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training, in NeurIPS 2022.
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yinan He, Yi Wang, Yali Wang, Yu Qiao, VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking, in CVPR 2023.
代表性成果3:视频多模态大模型-VideoChat系列
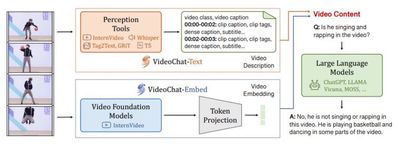
本成果提出了全球首个以视频为中心的多模态对话大模型 VideoChat,形成了对话驱动的通用视频理解能力,在重要多模态视频理解数据集上面取得了领先性能。VideoChat 相关技术被应用到快手可灵大模型的研发工作,GitHub 星标超过 3000。最近提出了 VideoChat-Online 和 VideoChat-Flash 版本,从交互形式和高效长时建模方面,进一步提升了 VideoChat 综合性能。
相关论文:
Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, Yu Qiao, VideoChat: Chat-Centric Video Understanding, arXiv:2305.06355
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, Yu Qiao, MVBench: A Comprehensive Multi-modal Video Understanding Benchmark, in CVPR 2024.
Xiangyu Zeng, Kunchang Li, Chenting Wang, Xinhao Li, Tianxiang Jiang, Ziang Yan, Songze Li, Yansong Shi, Zhengrong Yue, Yi Wang, Yali Wang, Yu Qiao, Limin Wang, TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning, in ICLR 2025
Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, Yu Qiao, Yali Wang, Limin Wang, VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling, arXiv:2501.00574
Zhenpeng Huang, Xinhao Li, Jiaqi Li, Jing Wang, Xiangyu Zeng, Cheng Liang, Tao Wu, Xi Chen, Liang Li, Limin Wang, Online Video Understanding: A Comprehensive Benchmark and Memory-Augmented Method, in CVPR 2025.
代表性成果4:书生视频大模型-InternVideo系列
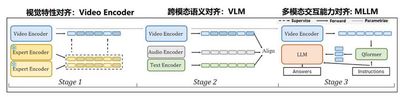
本成果提出了全球首个通用视频理解大模型 InternVideo:在 2022 年发布了视频基础表征版本 InternVideo 1.0,在视频基础感知、视频时空解析、视频开发识别等重点任务取得了世界领先水平;在 2024 年发布了视频多模态理解版本 InternVideo 2.0,在超过 60 种视频理解任务上面取得领先性能,包括识别检索、开放问答、高阶推理等等;在 2025 年发布了深层次视频时空理解版本 InternVideo 2.5,在视频理解跨度和粒度上实现了显著性能提升,模型“记忆力”更是较前代提升了 6 倍。
相关论文:
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jiashuo Yu, Yali Wang, Limin Wang, Yu Qiao, InternVideo: General Video Foundation Models via Generative and Discriminative Learning, arXiv:2212.03191
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Jilan Xu, Zun Wang, Yansong Shi, Tianxiang Jiang, Songze Li, Hongjie Zhang, Yifei Huang, Yu Qiao, Yali Wang, Limin Wang, InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding, in ECCV 2024.
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xiangyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, Min Dou, Kai Chen, Wenhai Wang, Yu Qiao, Yali Wang, Limin Wang, InternVideo2. 5: Empowering Video MLLMs with Long and Rich Context Modeling, arXiv: 2501.12386