团队成员
重要成果简介
南京大学大模型知识增强研究小组在人工智能、知识图谱、自然语言处理等国际高水平会议和期刊上发表论文20余篇,承担了华为、腾讯、智源、百川、国家电网、中电科等十余项大模型相关研发项目。
代表性成果1:语言模型与图模型高效协同
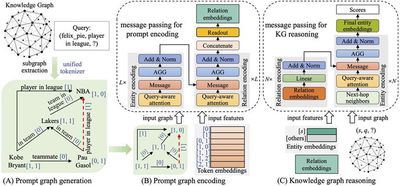
大型语言模型(LLM)具有知识缺失和难以更新内部知识等问题,因此常常深陷“幻觉”问题。知识图谱存储的海量结构化知识,为这一问题的解决提供了数据基础。近年来研究小组基于“基座模型-知识注入-检索增强”的路线开展深入研究,在高水平国际会议上发表了一系列成果:在 NeurIPS 2024 提出国内首个知识图谱基座模型,具有编码任意新知识图谱的强泛化能力,能够实现多源知识库的通用表征并支持高频次知识更新,该基座模型在 43 个各类任务的数据集上取得了最佳性能;在 NAACL 2024 提出一种基于嵌入式知识适配器与指令微调的 LLM 增强方法,该方法仅需微调少量参数便可有效注入图谱中的可靠知识,并具备参数高效、可灵活拔插等优点,在多个自然语言问答任务中展现了高性能与高效率;在 NAACL 2025 中提出一种基于知识图谱检索增强生成的问答方法,该方法基于事实型知识为检索块提供更多链接,并基于知识扩展技术来组织检索结果,在多个多跳问答数据集上实现了性能提升。
相关论文:
代表性成果2:大模型可控生成
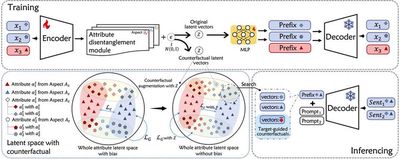
随着大模型的快速发展,确保大模型生成内容的属性可控至关重要,这包括对情感倾向、主题类型等多方面的调控能力。研究小组在 ACL 2024 研究了不同属性方面交织形成的不平衡属性关联问题,通过引入解耦的反事实增强,在训练过程中缓解了大模型由不平衡属性关联导致的刻板印象问题,并在推理阶段进一步增强目标导向的属性关联性,优化大模型在多属性方面的控制生成效果;研究小组就蛋白质生成问题进行了探索,在 AAAI 2024 提出了一种多列表偏好优化策略对蛋白质大模型进行微调,缓解现有方法在蛋白质序列生成时功能性和结构稳定性方面表现不佳的问题;此外,研究小组在 ICDE 2024 结合知识图谱来研究模型的可解释性,设计了基于语义匹配的解释生成方法,构建了人可理解的对齐依赖图来解释模型在实体对齐任务上的决策过程,在多个标准数据集上取得了最优效果,证实了方法解释结果的忠实性与可信度。
相关论文:
代表性成果3:领域大模型构建
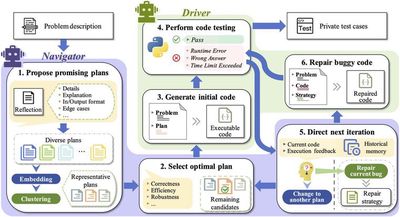
领域大模型的构建对于提升特定行业的智能化水平至关重要。相比通用大模型,领域大模型能够更精准地理解专业知识,提供高质量的决策支持,提高应用落地的可靠性和可解释性。在医疗领域,研究小组研发“超医”大模型,实现糖尿病、高血压等慢性病的个性化健教处方生成,辅助诊疗和智能随访,已为上海和南京的 20 家基层卫生服务中心提供在线服务。在软件领域,研究小组构建代码大模型,辅助代码生成和优化,探索智能化开发的前沿进展。