团队成员
重要成果简介
南京大学自然语言处理研究组长期从事自然语言处理、机器翻译等相关方向研究。在大模型时代,主要关注模型的知识、推理和多语言能力等方面的提升,开展了大语言模型的知识学习,大语言模型的翻译能力评估和激发、大语言模型能力的跨语言迁移以及多语言知识能力对齐等研究。
代表性成果1:LLM的知识学习偏好

LLM如何学习包含冲突知识的数据是一个值得深入研究的科学问题。该工作通过在合成知识上的实验,揭示了大语言模型面临冲突知识时,更加倾向于偏好正式的、拼写正确的文本。进一步分析发现,包含特定特征的文本与其他数据的一致性程度是决定模型学习偏好程度的关键因素。一致性越高,模型对该特征的偏好越强。通过调整不同特征的知识一致性程度,我们可以为模型注入新的知识学习偏好,并可以消除甚至反转模型中现存的偏好。该工作获得EMNLP2024 Outstanding Paper Award。
相关论文:



代表性成果2:大语言模型的翻译能力评估和激发

该方面工作系统地评测了包括ChatGPT在内的一系列大语言模型在102种语言,202个以英文为核心的翻译方向上的多语言机器翻译能力,探究了使用大语言模型进行多语言机器翻译的优势与挑战。研究发现:即使是最强的大语言模型(ChatGPT),仍然在83.33%的翻译方向上落后于强大的有监督基线模型(NLLB)。经过进一步的分析实验,我们发现在机器翻译任务上,大语言模型展现出了一些新的工作模式。为后续大语言模型和机器翻译、多语言相关研究探索了方向。该工作两年内Google scholar被引293次。该研究还探索了基于多语言指令学习激发大语言模型翻译能力的可行性,并在能力激发的原理和泛化性等方面进行了探索。
相关论文:
代表性成果3:大语言模型能力的跨语言迁移
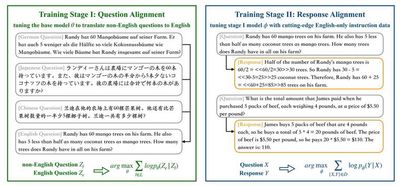
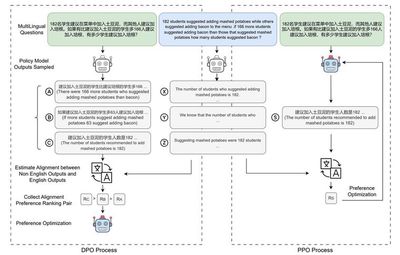
大语言模型的英文能力远高于其他语言。如何利用英文能力完成其他语言的任务,提升大语言模型在其他语言上的表现是一大挑战。我们尝试利用英文完成其他语言的任务(QAlign) 或者利用英文教会其他语言完成任务(MAPO),结果显示非英语可以取得大幅提升,缩小与英文差距。该工作受到Meta FAIR关注,在4月和11月的论文中引用我们的工作作为多语言偏好优化的代表工作。
相关论文:
代表性成果4:大语言模型知识和推理的跨语言传递
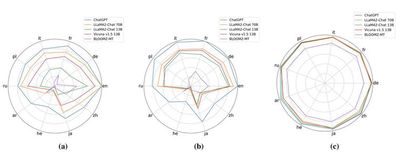
当前的大型语言模型虽然的英语能力很强,在其他语言中表现的能力都相对较弱。但这些语言的能力与英文是否尊在跨语言传递关系尚不明确。该方面研究提出了一个系统框架CLiKA来评估LLM在性能、一致性和传导性方面的跨语言知识对齐,探讨了多语言预训练和指令调优对对齐程度的影响。研究发现:所有测试的LLM的整体跨语言知识对齐,尤其是在传导性层面,都不令人满意,多语言预训练和指令调优都不能显著提高跨语言知识传导性。该方面研究还进一步关注了推理类问题的化语言传递。研究发现:知识检索是影响推理能力跨语言传递的重要原因;现有大模型大多能进行知识无关推理的跨语言迁移,而在推理涉及模型自身包含的知识时,迁移能力受到验证影响。进一步探索大语言模型能力的跨语言传递将为探索更加公平的大语言模型研究和应用带来可能。
相关论文:
代表性成果5:大语言模型的多语言预对齐


大语言模型往往在以英语为中心的语料上进行训练,训练语料中其余语言数据只占很少的比例。尽管如此,现有的LLM仍然展现出了一定的多语言性能。这是因为LLM执行多语言任务的能力与模型多语言对齐能力(为平行文本生成相似的表示)正相关,而近来的研究表明,LLM可以自发形成一定程度的多语言对齐。然而,这种自发形成的对齐能力仍然相对较弱,这导致模型在跨语言知识检索和跨语言行为一致上仍然存在较大问题。该工作提出了预对齐(PreAlign)框架,通过将对齐建立的阶段提前到预训练之前,来更好地实现跨语言的迁移效果。为训练更加语言通用的大语言模型提供了一种可行方案。
相关论文: