大模型机器学习算法与平台研究小组
团队成员
重要成果简介
成本(GPU硬件、电力等成本)高昂已经成为人工智能尤其是大模型可持续发展的主要障碍之一。南京大学计算机学院研发了高效能训练和推理机器学习算法,通过算法创新提升了大模型训练和推理的速度从而降低成本,或者说在同样成本下通过算法创新可以训练和部署更大更好的模型从而提升准确率。此外,基于创新的机器学习算法研发了大模型训练和推理平台与系统,支撑大模型的高准确率、低成本训练和部署。代表性成果如下:
代表性成果1:高效能分布式训练算法与平台
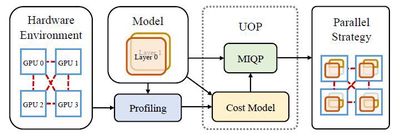
大模型的训练往往需要多机多卡的分布式训练。大模型的分布式训练挑战巨大,即使硬件足够,很多人大概率(我们实验中验证有64%-87%的概率)会因为超参数设置(模型怎么切分和排布、数据怎么切分和排布等)不合理而跑不出结果。此外,很多人在碰到大模型训练慢时只会想到增加GPU等硬件,而忽略了或者没意识到分布式训练算法的作用。实际上,分布式训练算法会极大地影响硬件的算力利用率、计算有效率和系统容错性。高效能分布式训练算法具有高算力利用率、高计算有效率和强系统容错性。用同样的硬件算力训练同一个模型,高效能分布式训练算法会比低效能分布式训练算法速度快,最高可能会快数倍甚至数十倍以上;或者说,训练同一个模型,高效能分布式训练算法会比低效能分布式训练算法成本低,最高可能会节省数倍甚至数十倍以上的算力成本。很多已有的分布式训练算法的效能较低,甚至可能导致机器和GPU卡越多、训练速度越慢的结果。我们从算力利用率、计算有效率和系统容错性等不同维度提出了一系列高效能分布式训练算法,包括通信优化算法、异步算法、鲁棒容错算法和自动并行算法等。此外,我们还研发了高效能分布式训练平台UniAP,是首个能实现层类并行策略(张量并行等)和层间并行策略(流水线并行等)联合优化的工作。给定模型和硬件平台,UniAP能够通过自动搜索找到最高效能的分布式训练方案,既解决了效率和成本问题(我们实验中,只采用并行策略优化算法而不叠加其他优化算法的情况下比已有的最好方法最高快3.8倍,比不采用并行策略优化的算法最高快9倍),也解决了很多人在大模型分布式训练时因为超参数设置(模型怎么切分和排布、数据怎么切分和排布等)不合理而跑不出结果的问题。我们还实现了UniAP跟国产AI计算卡的适配。相关工作为大模型训练的降本增效提供了核心技术和平台。
相关论文:
- Hao Lin, Ke Wu, Jie Li, Jun Li, Wu-Jun Li. UniAP: Unifying Inter- and Intra-Layer Automatic Parallelism by Mixed Integer Quadratic Programming. CVPR 2025.
- Shen-Yi Zhao, Chang-Wei Shi, Yin-Peng Xie, Wu-Jun Li. Stochastic Normalized Gradient Descent with Momentum for Large-Batch Training. SCIENCE CHINA Information Sciences (SCIS), 2024.
- Chang-Wei Shi, Yi-Rui Yang, Wu-Jun Li. Ordered Momentum for Asynchronous SGD. Advances in Neural Information Processing Systems (NeurIPS), 2024.
- Yi-Rui Yang, Chang-Wei Shi, Wu-Jun Li. On the Effect of Batch Size in Byzantine-Robust Distributed Learning. The Twelfth International Conference on Learning Representations (ICLR), 2024.
- Chang-Wei Shi, Shen-Yi Zhao, Yin-Peng Xie, Hao Gao, Wu-Jun Li. Global Momentum Compression for Sparse Communication in Distributed SGD. arXiv 2024.
代表性成果2:基于持续学习的高效能训练算法
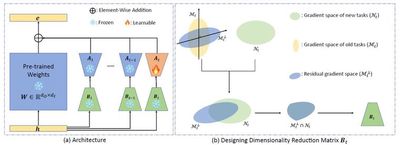
持续学习的目标是让模型能够持续学习新任务,同时保留解决旧任务的能力。这对于高效能训练大模型具有重要意义。目前,训练大模型通常需要依赖千卡甚至万卡 GPU 集群和海量数据,成本极为高昂。如果模型具备持续学习能力,新版本的大模型可以在旧版本的基础上进行增量训练,而无需重新回顾旧任务的数据,从而有望大幅降低训练开销。然而,现有的大模型缺乏持续学习能力,常常面临“灾难性遗忘”(Catastrophic Forgetting)问题,即在学习新任务后,由于参数发生改变,模型会丢失在旧任务上学到的知识,导致其在旧任务上的性能显著下降。为了实现持续学习,模型需要同时具备保持旧任务性能的能力(稳定性)和学习新任务的能力(可塑性)。实现持续学习将是推动大模型向更高效、更智能方向发展的关键。我们提出了一种新的基于参数高效微调的持续学习方法InfLoRA。InfLoRA向预训练模型中注入低秩分支重参数化预训练权重,并且我们的理论证明微调低秩分支等同于在一个由该低秩分支中的降维矩阵张成的子空间内直接微调预训练权重。然后,InfLoRA通过设计低秩分支中的降维矩阵来间接地设计该子空间,将其约束在一个不会干扰旧任务性能的范围内,在提升模型可塑性的同时保持稳定性(即克服或减轻灾难性遗忘),实现模型总体准确率的提升。InfLoRA是首个建立LoRA微调和全参数微调之间的关系、并基于此设计机制以克服遗忘的持续学习方法。相关工作从与分布式训练不同的角度为大模型训练的降本增效提供了核心技术。
相关论文:
- Yan-Shuo Liang, Wu-Jun Li, InfLoRA: Interference-Free Low-Rank Adaptation for Continual Learning, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2024.
代表性成果3:高效能推理算法与平台
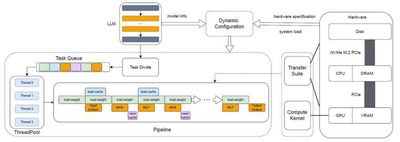
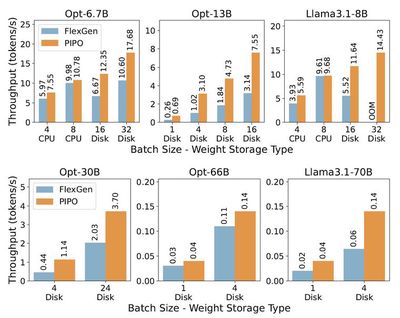
随着大模型能力越来越强大,应用数量和用户数量也快速增长,从而导致推理和部署所需的硬件成本也快速增长。此外,推理模型的流行进一步加剧了推理和部署所需硬件成本的增长。为了解决这一挑战,我们从模型压缩算法和推理系统架构上进行了创新,设计了高效能推理算法与平台。在模型压缩算法方面,我们提出了基于低秩字典的模型量化算法LCQ,可以让量化字典的秩大于1,而已有方法的量化字典的秩只能为1,LCQ通过增大量化字典的秩从而减小模型的量化损失,取得了比已有方法更高的准确率。在推理系统架构方面,卸载(Offloading)方法通过将部分模型存储在CPU内存甚至硬盘上,可以实现规模超出GPU显存容量的大模型的推理和部署。但现有Offloading框架(如FlexGen)因推理并发度低和硬盘利用不足,导致GPU利用率低从而严重限制推理性能。我们设计了叫做PIPO(Pipelined Offloading)的新型Offloading框架,可以根据输入模型和硬件系统的规格信息,自动求解最优的Offloading方案,从而可以选择合适的细粒度流水线策略。此外,PIPO还实现了数据传输的优化和CUDA底层计算内核的定制修改以提高推理并发程度,从而显著提升GPU利用率和推理吞吐量。实验表明,已有方法的GPU利用率不到40%,而PIPO可以将GPU利用率提升至90%以上,PIPO推理吞吐量(即推理速度)最高达到已有方法的3.1倍。相关工作为大模型推理和部署的降本增效提供了核心技术和平台。
相关论文:
- Wen-Pu Cai, Ming-Yang Li, Wu-Jun Li, LCQ: Low-Rank Codebook based Quantization for Large Language Models, in arXiv 2024.
- Yangyijian Liu, Jun Li, Wu-Jun Li, PIPO: Pipelined Offloading for Efficient Inference on Consumer Devices, in arXiv 2025.