具身决策大模型研究小组
团队成员
重要成果简介
具身决策大模型研究小组关注具身智能前沿技术研究,围绕搭建可泛化的具身智能体整体目标,在具身表征建模、具身策略学习、具身分层规划与执行等方向开展系列研究工作,取得如下代表性研究成果:
代表性成果1:时空预测驱动的具身视觉表征预训练模型STP
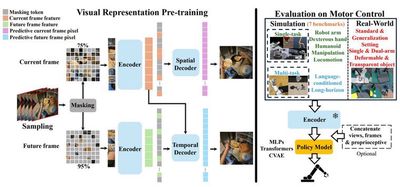
本成果利用大规模人类第一视角操纵视频数据集,以解耦的空间预测和时序预测作为自监督学习代理任务,提出了专用于机器人运动控制的图像表征模型STP。STP能够无监督地从视频数据中学习复杂场景的空间几何细节和人类行为的时序动力学属性,进而联合捕获图像中的内容特征和运动敏感特征。经过预训练的STP模型,无需微调即可直接迁移到机器人运动控制任务中,并在真实环境和七个仿真环境中的50多项任务中超越了现有基线方法。这些任务涵盖了单机械臂、双机械臂、三指灵巧手、五指灵巧手以及人形机器人的多种操纵与移动任务。
相关论文:
Jiange Yang, Bei Liu, Jianlong Fu, Bocheng Pan, Gangshan Wu, Limin Wang, Spatiotemporal Predictive Pre-training for Robotic Motor Control.
代表性成果2:三维渲染重建驱动的具身视觉表征预训练模型SPA
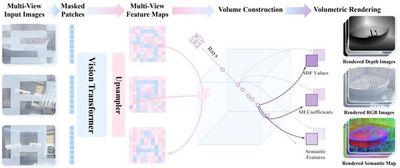
本成果提出了视觉表征学习框架SPA,通过增强三维空间感知来提高在具身智能任务中的表示学习能力。SPA从合成室内场景和真实世界机器人交互场景中构建了一个含有相机位姿、深度图以及语义特征图标注的大规模多视角数据集,并基于多视角图像和相机位姿构建三维体积特征,进而结合掩码技术及可微神经渲染生成RGB图、深度图和语义图,同时通过Eikonal正则化和SDF监督进一步提升三维几何一致性。经过6000 GPU小时训练的SPA在真实环境和八个仿真环境的200余项任务中平均性能优于其他基线方法,其中在高达30.3%的任务中排名第一。
相关论文:
Haoyi Zhu, Honghui Yang, Yating Wang, Jiange Yang, Limin Wang, Tong He, SPA: 3D Spatial-Awareness Enables Effective Embodied Representation, in ICLR 2025.
代表性成果3:多域数据学习驱动的具身预测与决策模型Tra-MoE
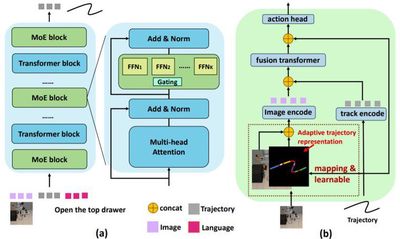
本成果提出了基于稀疏门控混合专家架构的轨迹预测模型Tra-MoE。Tra-MoE通过更好地平衡参数协作化和参数专用化进而从大规模、跨域、无动作标签的视频数据中学习泛化性更强且性能超过同等参数量密集基线的轨迹预测模型,成功实现了通专融合的网络架构。Tra-MoE有效结合了不同物理引擎渲染的仿真视频以及真实环境中人类、单机械臂和双机械臂的跨智能体异构操纵视频,在跨智能体学习领域中具有重要的研究前景。此外,本成果提出了一种自适应的策略条件化技术,能够更有效地利用预测轨迹对机器人策略进行引导,从而显著提升下游机器人策略执行的性能。
相关论文:
Jiange Yang, Haoyi Zhu, Yating Wang, Gangshan Wu, Tong He, Limin Wang, Learning Trajectory Prediction Model from Multiple Domains for Adaptive Policy Conditioning, in CVPR 2025.
代表性成果4:可泛化的分层规划与执行框架与系统
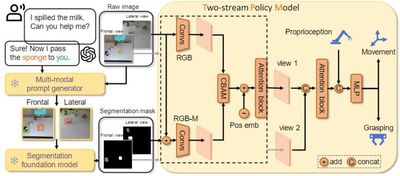
目前在互联网规模数据上训练的视觉与语言模型在各种任务和场景下取得优异的泛化性,然而由于无法与真实世界交互,它们缺乏足够的物理知识。相反地,机器人策略可以通过模仿学习从人类示教数据中学习技能,但机器人数据采集成本极高且同质化严重,这导致目前的机器人操纵系统泛化性较差。本成果提出将语言推理的掩码模态集成到端到端策略模型中来实现样本高效的机器人操作泛化,该模态融入了互联网基础模型中蕴含的语义、几何和时序关联先验知识,进而结合了互联网基础模型的泛化性和模仿学习捕捉人类多模动作分布的能力。本成果成功打通了机器人系统中从感知推理规划到决策执行的大小脑闭环,得到斯坦福大学李飞飞团队和加州大学伯克利分校Jitendra MALIK团队的引用,其采用的大小脑分层方案也在全球具身智能头部公司Figure AI和Physical Intelligence中所使用,具有较高的社会应用前景和价值。
相关论文:
Jiange Yang, Wenhui Tan, Chuhao Jin, Keling Yao, Bei Liu, Jianlong Fu, Ruihua Song, Gangshan Wu, Limin Wang, Transferring Foundation Models for Generalizable Robotic Manipulation, in WACV 2025 Oral.