团队成员
重要成果简介
大模型可控生成研究小组长期从事大语言模型和多模态模型的生成相关研究。目前,研究小组致力于研究大模型的可控生成技术以增强大模型在特定属性上的输出,专注于大模型的干预和引导、多模态大模型的条件控制、大模型的神经元和激活定位等技术来控制其生成。代表性成果如下:
代表性成果1:基于大语言模型引导技术的可控生成
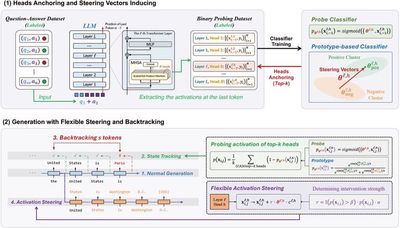
大语言模型引导技术由于其可以直接修改输出的激活且无需微调大语言模型受到了广泛关注。之前的方法往往无法判断是否需要干预、准确地估计干预强度以及动态地决定干预的时机。为此,本研究提出了一个灵活的激活引导技术,通过在生成的每一步中追踪生成内容偏离的程度来灵活地决定干预的强度以及时机。我们进一步提出回溯机制来把已经偏离的内容引导到正确方向。
相关论文:
代表性成果2:基于模型干预的大模型表示生成技术
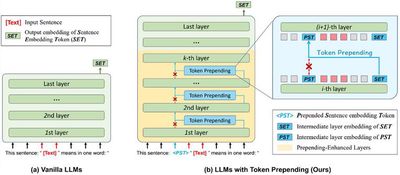
从大语言模型中抽取句子嵌入由于其无需数据和微调受到了广泛的注意。之前的方法通常基于提示来引出大语言模型编码句子嵌入的能力。然而,此类方法受限于大语言模型的单向注意力机制且没有有效捕捉句子的核心语义。为此,(1) 研究小组提出了基于词元前置的方法来克服大语言模型单向注意力的不足。(2) 研究小组提出了对比提示的方法通过引入辅助提示和推断时引导使其编码句子的核心语义。
相关论文:
Zifeng Cheng, Zhonghui Wang, Yuchen Fu, Zhiwei Jiang, Yafeng Yin, Cong Wang, Qing Gu. Contrastive Prompting Enhances Sentence Embeddings in LLMs through Inference-Time Steering, in ACL 2025.
代表性成果3:基于多模态大模型的生成技术
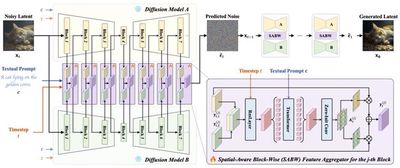
随着视觉生成技术的快速发展,增强或控制生成内容显得尤为重要。(1) 为了提升自动提示在不同扩散模型上的泛化能力,研究小组提出了两阶段方法 AP-Adapter。在第一阶段,AP-Adapter 利用 LLM 对自然语言描述进行自动关键词提示优化;在第二阶段,该方法通过领域原型的表示增强机制,对多模型间的特征差异进行调和,使提示生成能够适配于未见模型。(2) 为了动态整合多个扩散模型的能力并充分发挥其优势,研究小组提出了 AFA 方法。AFA 通过设计轻量级的空间感知块级特征聚合器,根据不同状态动态调整各模型的特征贡献,从而实现特征级别的动态融合。(3) 为了解决音频驱动的人像视频生成中多模态控制信号权重不均衡的问题,研究小组提出了 V-Express。该方法引入条件随机失活操作以及渐进式训练策略,使弱控制信号能够有效发挥作用,并与强控制信号协同工作。(4) 为了解决现有手语视频生成方法仅依赖单一粗粒度条件导致生成效果受限的问题,研究小组提出了 SignViP。该方法通过离散化多细粒度条件,结合多条件 token 翻译与联合训练,有效提升了生成视频的自然度和语义表达能力。
相关论文:
Yuchen Fu, Zhiwei Jiang, Yuliang Liu, Cong Wang, Zexuan Deng, Zhaoling Chen, Qing Gu. AP-Adapter: Improving Generalization of Automatic Prompts on Unseen Text-to-Image Diffusion Models, in NeurIPS 2024.
Cong Wang, Kuan Tian, Yonghang Guan, Fei Shen, Zhiwei Jiang, Qing Gu, Jun Zhang. Ensembling Diffusion Models via Adaptive Feature Aggregation, in ICLR 2025.
Cong Wang, Kuan Tian, Jun Zhang, Yonghang Guan, Feng Luo, Fei Shen, Zhiwei Jiang, Qing Gu, Xiao Han, Wei Yang. V-Express: Conditional Dropout for Progressive Training of Portrait Video Generation, in arXiv:2406.02511.