云端大模型系统研究小组
团队成员
重要成果简介
云端大模型系统研究小组致力于探索云环境下大模型训练、推理与部署的系统级性能优化技术。团队重点研究方向包括:云端大模型的存储管理优化、高效分发加载机制、训练流程调优策略以及推理性能优化等关键技术。在开展前沿学术研究的同时,团队与阿里云、华为、蚂蚁集团、小红书等业界领先企业保持深度产学研合作,推动研究成果在工业界的实际应用落地及开源社区建设。在高年级本科生/研究生教育方面,开设大模型推理系统内核原理与优化技术专题课程(试点教学阶段,内部邀请),系统培养学生对大模型推理流程的深入理解能力及定制化优化的实践进阶能力。以下展示团队的部分代表性研究成果:
代表性成果1:基于热度感知的大模型推理系统KV Cache卸载与预取调度优化
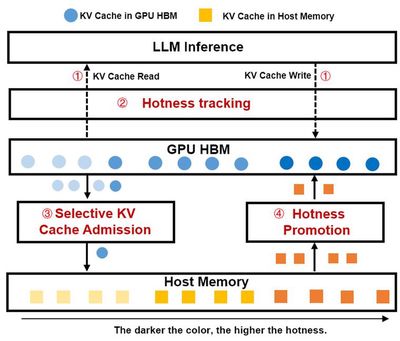
随着大语言模型(LLM)在多任务场景中展现出卓越性能,提示工程技术(如Few-Shot Learning、Chain-of-Thought、RAG)已成为优化模型输出的核心手段。然而,此类方法通常依赖包含大量共享前缀(如系统指令、模板、检索文档)的结构化提示,导致推理过程中KV Cache重复存储,显著增加GPU显存占用,进而限制系统并发能力与吞吐量。尽管现有系统(如vLLM、SGLang)已尝试通过KV Cache前缀共享优化显存效率,但仍存在两大关键挑战:(1)动态热度追踪不足——现有方法难以精准量化前缀KV Cache的热度变化;(2)异构存储协同低效:缺乏CPU内存与GPU显存间的高效协同调度机制。本工作针对大模型推理系统长在提示前缀共享场景下KV Cache显存占用高、多级存储传输开销大问题,本文提出HotPrefix——一种面向长提示前缀共享场景的高效KV Cache管理与调度框架。其核心创新包括:(1)轻量级热度感知机制:通过动态构建前缀树节点热度模型,实现细粒度KV Cache访问模式追踪;(2)异构存储协同调度:选择性将低频访问的KV Cache卸载至主机内存,并通过异步流水线将高热度前缀预加载至显存;(3)计算-存储联合优化:最大化复用已计算的KV Cache,降低预填充阶段计算开销,提升显存命中率。HopPrefix能够显著提升共享前缀场景的端到端推理延迟和吞吐量,相比SGLang和vLLM最高可降低2倍和2.25倍推理时延,可用于LLM推理长提示和RAG等应用服务。
相关论文:
Yuhang Li, Rong Gu, Chengying Huan, Zhibin Wang, Renjie Yao, Chen Tian, Guihai Chen. HotPrefix: Hotness-Aware KV Cache Scheduling for Efficient Prefix Sharing in LLM Inference Systems, accepted, to appear in SIGMOD 2026. (CCF-A, 南京大学是独立完成单位)
代表性成果2:面向云原生深度学习训练作业的数据集抽象和缓存弹性编排系统
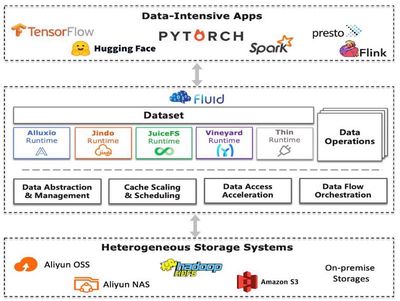
近年来,以大模型为代表的深度学习技术已在文本理解、多模态感知等领域取得突破性进展。然而,深度学习的计算密集性与数据密集性特征,使其高度依赖高性能计算集群与海量训练数据。为满足弹性资源需求,云原生技术逐渐成为深度学习训练的主流选择,但其计算存储分离架构引入了显著的数据I/O瓶颈,具体体现在数据访问效率低、资源动态适配难、缓存共享能力弱。本文提出Fluid——面向云原生深度学习训练的数据抽象与弹性缓存编排系统,其核心贡献包括:(1)统一数据抽象层:通过声明式数据集(Dataset CRD)封装分布式数据源,实现用户无感知的数据访问优化;(2)动态缓存弹性扩缩容:基于实时训练速度监控(Throughput-Aware Autoscaling),动态调整缓存资源配额,缓解数据访问性能瓶颈。(3)全局缓存感知调度:构建数据集热度模型与缓存拓扑感知机制,跨作业复用缓存数据,提升集群级数据局部性。实验证明,该系统在单作业和多作业场景下分别能获得约3倍和约2倍的性能提升。Fluid从最初学术系统原型,经过和阿里云、Alluxio等大厂的深度合作,已经发展成为国际云原生开源基金会的官方开源项目(顾荣老师担任Fluid开源社区主席,实验室多位同学成长为Fluid开源项目Committer并入职大厂工作),开源用户包括阿里云、百度云、天翼云、360公司、小米、OPPO、微博等10余个行业领军企业,被评为2021年中国信通院OSCAR尖峰开源项目,并获得2022年中国开源创新大赛一等奖。
相关论文:
Rong Gu, Kai Zhang, Zhihao Xu, Yang Che, Bin Fan, Haojun Hou, Haipeng Dai, Li Yi, Yu Ding, Guihai Chen, Yihua Huang. Fluid: Dataset Abstraction and Elastic Acceleration for Cloud-native Deep Learning Training Jobs, in ICDE 2022. (CCF-A, 南京大学是牵头完成单位)
Rong Gu, Zhihao Xu, Yang Che, Xu Wang, Haipeng Dai, Kai Zhang, Bin Fan, Haojun Hou, Li Yi, Yu Ding, Yihua Huang, Guihai Chen. High-level Data Abstraction and Elastic Data Caching for Data-intensive AI Applications on Cloud-native Platforms, in IEEE TPDS 2023. (CCF-A, 南京大学是牵头完成单位)
Fluid开源项目与社区的官网链接介绍: