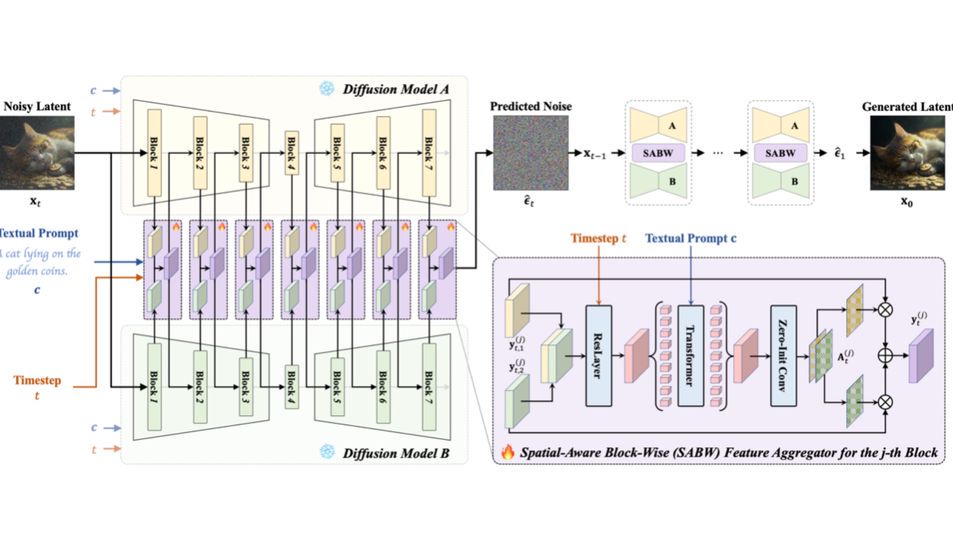
研究小组
大模型中心开展大模型系统架构、学习算法和领域应用的创新研究,为新一代人工智能提供核心技术。主要研究方向包括:面向大模型的可扩展系统架构、面向大模型的高效能机器学习算法与平台、大模型知识增强学习算法,以及语言大模型、多模态大模型、科学大模型、具身决策大模型、智能体系统,以及神经符号推理系统等。
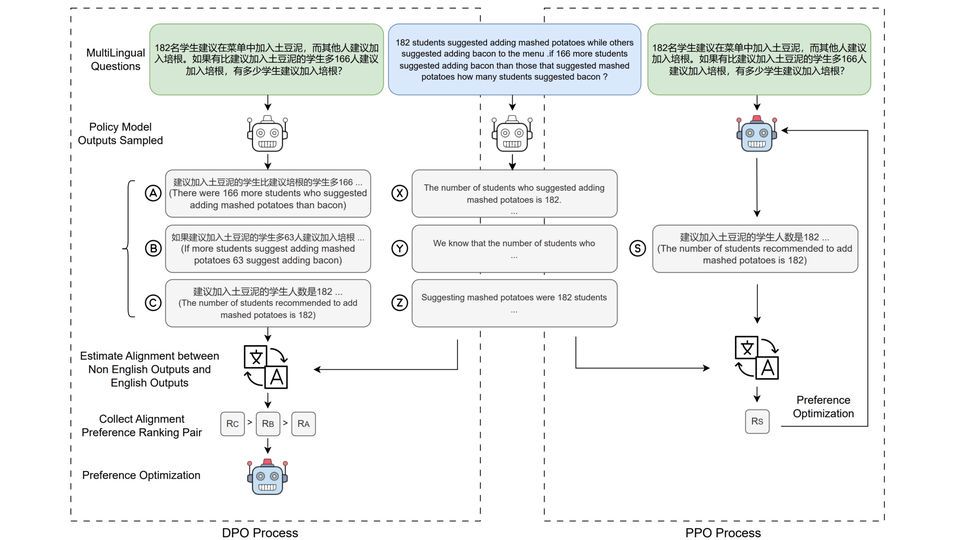
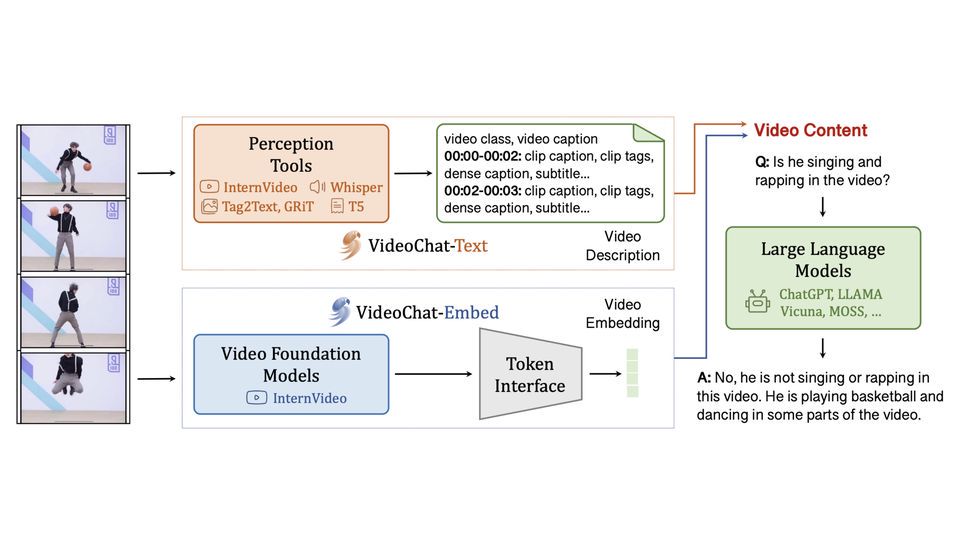
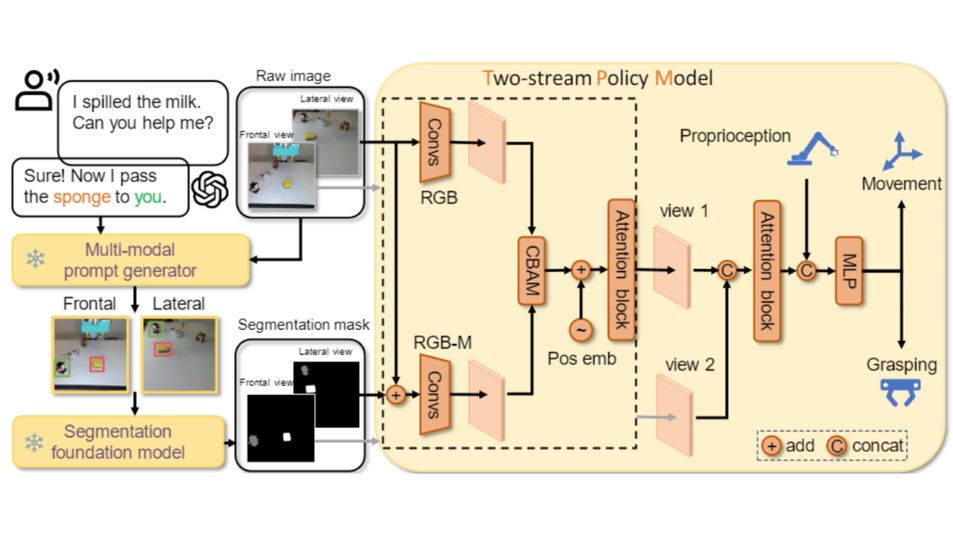
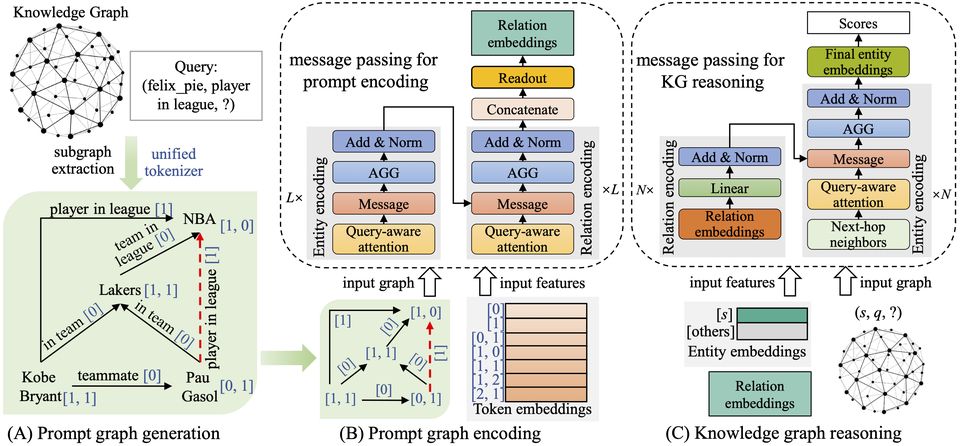
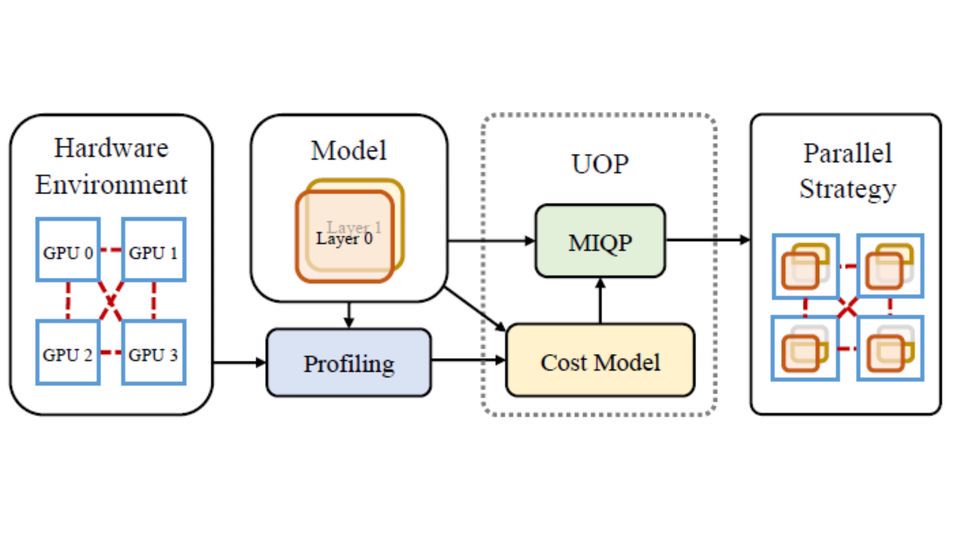
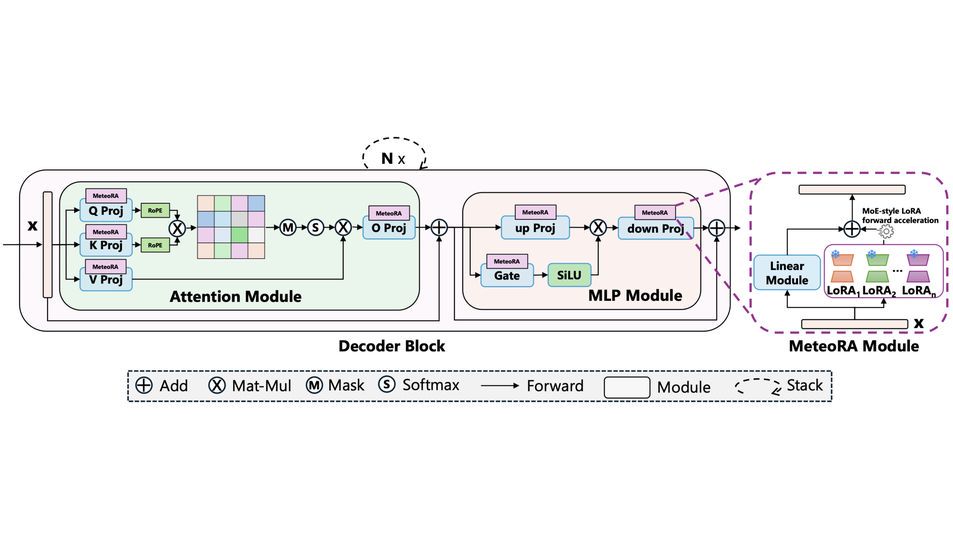
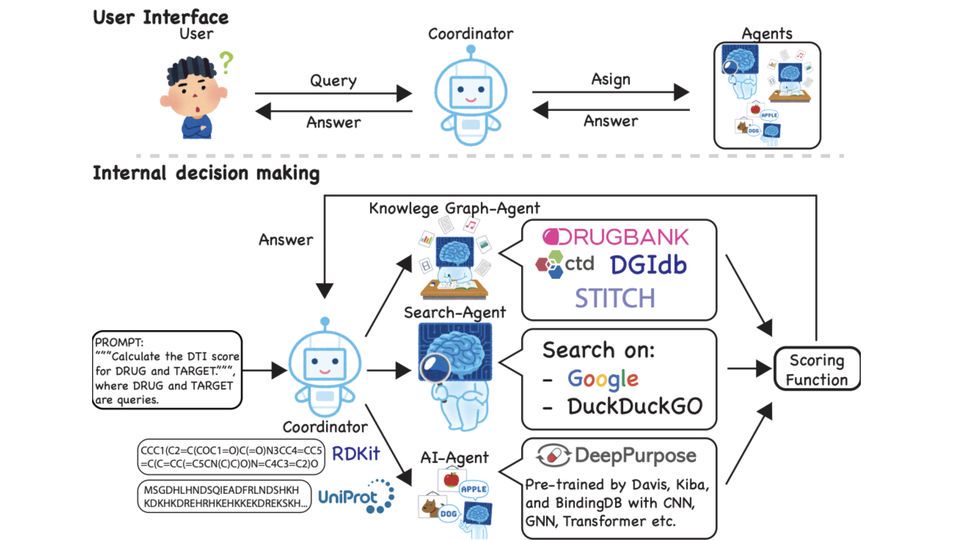
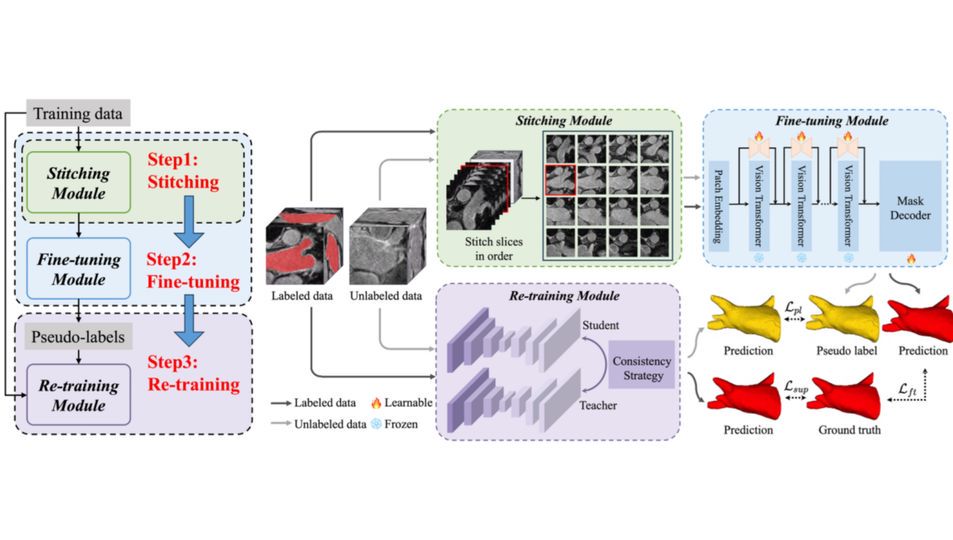
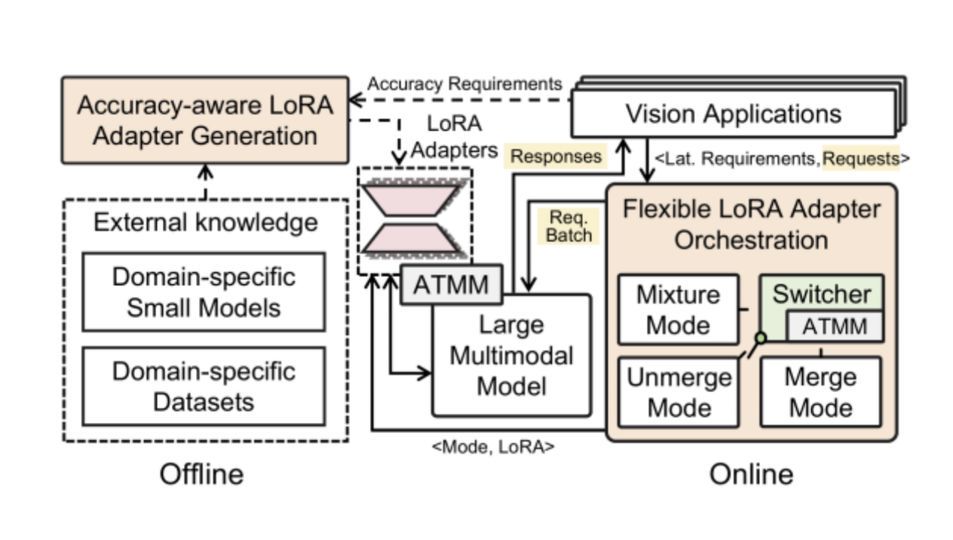
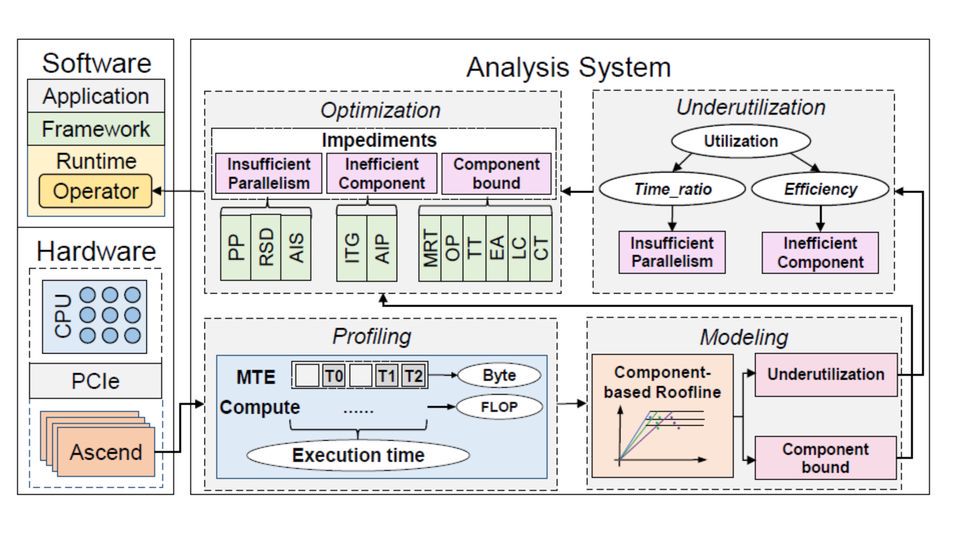
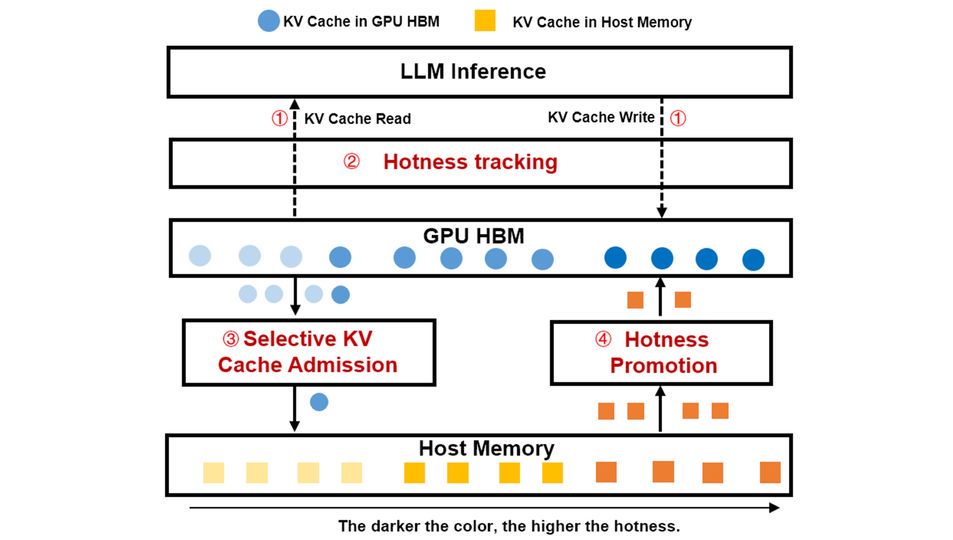
大模型中心开展大模型系统架构、学习算法和领域应用的创新研究,为新一代人工智能提供核心技术。主要研究方向包括:面向大模型的可扩展系统架构、面向大模型的高效能机器学习算法与平台、大模型知识增强学习算法,以及语言大模型、多模态大模型、科学大模型、具身决策大模型、智能体系统,以及神经符号推理系统等。