Large Language Model System Research Group
Team Members
Introduction to Key Achievements
The NASA research group of Nanjing University, in collaboration with renowned institutions such as Pengcheng Laboratory and Huawei Technologies Co., Ltd., has conducted comprehensive and in-depth research on key topics including large model training/inference performance and power consumption. The research achievements have not only been published at top conferences in the field of computer architecture, but have also been successfully deployed in relevant enterprises, making positive contributions to bridging the gap between theory and practice. Below are some representative achievements:
Representative Achievement 1: AI Operator Performance Modeling and Optimization for Ascend Architecture
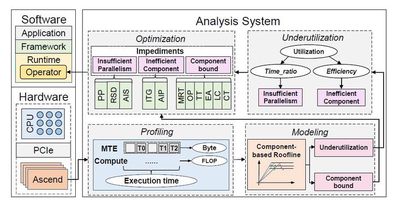
This research proposes a component-based Roofline model for analyzing and optimizing AI operator performance on the Huawei Ascend NPU architecture. As a dedicated AI accelerator, Ascend features unique compute units and memory transfer designs, but its complexity poses challenges for user-level performance optimization. The traditional Roofline model suffers from visualization complexity and inaccurate performance evaluation on Ascend.
To address this, the study introduces the concept of component abstraction, attributing operator performance bottlenecks to component bounds or insufficient utilization. With the improved component Roofline model, researchers can identify bottleneck components and perform targeted optimizations. The study details three real operator optimization cases, including Add_ReLU, Depthwise, and AvgPool, demonstrating how the improved Roofline analysis identifies bottlenecks and guides optimization, and summarizes common operator bottlenecks and optimization strategies.
In experiments, researchers optimized models from 11 real-world deep learning training and inference tasks, covering vision, natural language processing, recommendation systems, and large language models. Results show computation time speedups ranging from 1.08x to 2.70x, and overall speedups from 1.07x to 2.15x. In addition, 41 optimized operators have been integrated into the Ascend operator library. These achievements not only improve model performance but also provide valuable insights for future AI-specific architecture design.
Related paper:
Yuhang Zhou, Zhibin Wang, Guyue Liu, Shipeng Li, Xi Lin, Zibo Wang, Yongzhong Wang, Fuchun Wei, Jingyi Zhang, Zhiheng Hu, Yanlin Liu, Chunsheng Li, Ziyang Zhang, Yaoyuan Wang, Bin Zhou, Wanchun Dou, Guihai Chen, and Chen Tian. Squeezing Operator Performance Potential for the Ascend Architecture, in ASPLOS 2025.
Representative Achievement 2: Fine-Grained Energy Optimization during Model Training

As the number of cards used for large model training increases, energy consumption becomes a growing concern, making energy optimization during model training an important topic. This research leverages the millisecond-level dynamic frequency scaling (DVFS) capability provided by Huawei Ascend NPU to perform fine-grained energy optimization during model training. While millisecond-level DVFS operators offer more opportunities for energy optimization, they also introduce an explosive search space for DVFS strategies, posing challenges for energy optimization.
To address this challenge and achieve significant energy savings with minimal performance loss, we optimized the end-to-end process of energy tuning. Specifically, we found that the number of cycles consumed by an operator and the AICore frequency exhibit a piecewise linear relationship, with the slope increasing as frequency increases. That is, the relationship between operator cycles and AICore frequency is a convex function. Based on this, we built an accurate operator performance model, which achieves an average prediction error of only 1.96% on over 30,000 data points. Furthermore, hardware power consumption consists of dynamic and static power, with static power determined by subthreshold leakage and gate oxide currents, and subthreshold leakage being linearly related to temperature. Our work incorporates temperature-related terms in power modeling, improving accuracy, with an average prediction error of only 4.62% on multiple common workloads. Finally, when generating DVFS strategies, we effectively reduced the search space and accelerated strategy optimization through operator classification, preprocessing, and genetic algorithm-based search. With a 2% performance loss target, we achieved an average performance loss of only 1.59% while reducing AICore energy consumption by 15.27%.
Related paper:
Zibo Wang, Yijia Zhang, Fuchun Wei, Bingqiang Wang, Yanlin Liu, Zhiheng Hu, Jingyi Zhang, Xiaoxin Xu, Jian He, Xiaoliang Wang, Wanchun Dou, Guihai Chen, and Chen Tian. Using Analytical Performance/Power Model and Fine-Grained DVFS to Enhance AI Accelerator Energy Efficiency, in ASPLOS 2025.