Multimodal Large Model Research Group
Team Members
Brief Overview of Key Achievements
Nanjing University, Shanghai Artificial Intelligence Laboratory, and other institutions have jointly developed a series of video large models and multimodal large models, achieving world-leading performance on visually-centered multimodal understanding tasks. The representative achievements are as follows:
Representative Achievement 1: Shusheng Multimodal Large Model - InternVL Series
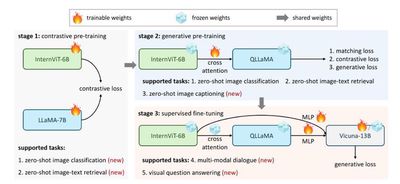
The rapid growth of large language models (LLMs) has opened up countless possibilities for multimodal AGI systems. However, progress in visual and vision-language foundation models (which are also key components of multimodal AGI) has not kept pace with LLMs. In this work, we designed a large vision-language foundation model (InternVL) that extends the visual foundation model to 6 billion parameters and gradually aligns it with LLMs, using web-scale image-text data from various sources. The model can be widely applied to 32 general vision-language benchmarks and has achieved top performance on these benchmarks, including visual perception tasks (such as image-level or pixel-level recognition), vision-language tasks (such as zero-shot image/video classification, zero-shot image/video text retrieval), and linking with LLMs to create multimodal dialogue systems. It possesses powerful visual capabilities and can serve as an excellent alternative to ViT-22B.
Relevant paper:
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, Jifeng Dai, InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, in CVPR 2024.
Representative Achievement 2: Video Foundation Representation Model - VideoMAE Series
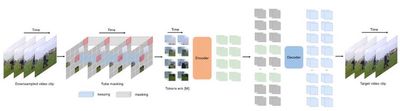
This work proposes the video masked autoencoder VideoMAE v1 & v2, successfully training the first video Transformer model with 1 billion parameters and breaking through the performance bottleneck of self-supervised video representation learning. The VideoMAE series has been cited over 1500 times and has become a benchmark method in the field of self-supervised video learning. It has been extended by institutions such as Oxford University, Microsoft, Google, Meta, and others, and became the first video Transformer model included by the open-source community Hugging Face, with global downloads exceeding 3.2 million, ranking first in Hugging Face’s video recognition model downloads.
Relevant papers:
Zhan Tong, Yibing Song, Jue Wang, Limin Wang, VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training, in NeurIPS 2022.
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yinan He, Yi Wang, Yali Wang, Yu Qiao, VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking, in CVPR 2023.
Representative Achievement 3: Video Multimodal Large Model - VideoChat Series
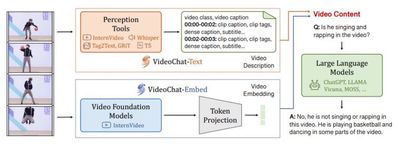
This work presents the world’s first video-centric multimodal dialogue large model, VideoChat, which establishes dialogue-driven general video understanding capabilities and achieves leading performance on important multimodal video understanding datasets. VideoChat-related technologies have been applied in the development of Kuaishou Keling large model, with over 3000 GitHub stars. Recently, the VideoChat-Online and VideoChat-Flash versions have been introduced, further enhancing VideoChat’s comprehensive performance through improved interaction and efficient long-term modeling.
Relevant papers:
Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, Yu Qiao, VideoChat: Chat-Centric Video Understanding, arXiv:2305.06355
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, Yu Qiao, MVBench: A Comprehensive Multi-modal Video Understanding Benchmark, in CVPR 2024.
Xiangyu Zeng, Kunchang Li, Chenting Wang, Xinhao Li, Tianxiang Jiang, Ziang Yan, Songze Li, Yansong Shi, Zhengrong Yue, Yi Wang, Yali Wang, Yu Qiao, Limin Wang, TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning, in ICLR 2025
Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, Yu Qiao, Yali Wang, Limin Wang, VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling, arXiv:2501.00574
Zhenpeng Huang, Xinhao Li, Jiaqi Li, Jing Wang, Xiangyu Zeng, Cheng Liang, Tao Wu, Xi Chen, Liang Li, Limin Wang, Online Video Understanding: A Comprehensive Benchmark and Memory-Augmented Method, in CVPR 2025.
Representative Achievement 4: Shusheng Video Large Model - InternVideo Series
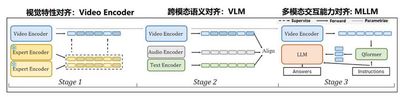
This work presents the world’s first general video understanding large model, InternVideo: In 2022, the video foundation representation version InternVideo 1.0 was released, achieving world-leading performance in key tasks such as video basic perception, video spatiotemporal parsing, and video action recognition; in 2024, the multimodal video understanding version InternVideo 2.0 was released, achieving leading performance on more than 60 video understanding tasks, including recognition retrieval, open-domain question answering, and high-level reasoning; in 2025, the deep video spatiotemporal understanding version InternVideo 2.5 was released, achieving significant performance improvements in video understanding span and granularity, with the model’s “memory” enhanced by 6 times compared to its predecessor.
Relevant papers:
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jiashuo Yu, Yali Wang, Limin Wang, Yu Qiao, InternVideo: General Video Foundation Models via Generative and Discriminative Learning, arXiv:2212.03191
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Jilan Xu, Zun Wang, Yansong Shi, Tianxiang Jiang, Songze Li, Hongjie Zhang, Yifei Huang, Yu Qiao, Yali Wang, Limin Wang, InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding, in ECCV 2024.
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xiangyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, Min Dou, Kai Chen, Wenhai Wang, Yu Qiao, Yali Wang, Limin Wang, InternVideo2. 5: Empowering Video MLLMs with Long and Rich Context Modeling, arXiv:2501.12386