Medical Imaging Large Model Research Group
Team Members
Overview of Key Achievements
The Nanjing University Medical Imaging Large Model Research Group has long been devoted to the field of intelligent medical imaging, focusing on efficient training and low-cost fine-tuning of large models to explore cutting-edge applications in medical image segmentation, auxiliary diagnosis, and precision treatment. In the face of steep annotation costs in medical imaging, the group focuses on methods such as sparse supervision, efficient data utilization, and pseudo-label optimization to reduce dependence on large-scale manual annotations while enhancing model generalization and robustness.
Key Achievement 1: Foundation Model-Guided Universal Semi-Supervised 3D Medical Image Segmentation Framework
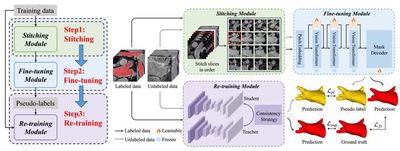
Universal vision foundation models such as SAM perform excellently in fully supervised medical image segmentation but still require large volumes of high-quality annotated data. In this context, can we design a universal semi-supervised medical image segmentation framework that simultaneously leverages SAM’s generalization capability and reduces the burden of complex annotations? Observations indicate the framework should exhibit pseudo-label effectiveness, parameter efficiency, and excellent compatibility. In view of these factors, this study proposes a three-stage framework—Stitching, Fine-tuning, and Re-training (abbreviated as SFR). The stitching module aligns resolutions between 3D medical images and pre-trained natural images. Subsequently, the stitched images fine-tune SAM and guide the training of a small-scale 3D semi-supervised segmentation model, ultimately maintaining a parameter scale similar to traditional segmenters such as V-Net. The SFR framework is easily compatible with various popular semi-supervised methods. Results on multiple datasets with moderate annotations (e.g., 20% labeled data) achieve performance comparable to full supervision, while extremely limited annotations (only one sample) still yield significant improvements.
Related Paper:

Key Achievement 2: Foundation Model-Guided Universal Weakly-Supervised Medical Image Segmentation Framework
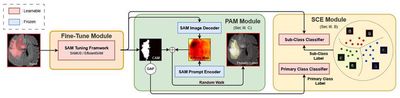
Most approaches that adapt vision foundation models such as SAM to medical imaging tasks rely on large amounts of labeled data, whereas weakly-supervised segmentation uses only category labels to greatly reduce annotation effort. However, SAM lacks an effective mechanism to handle the co-occurrence phenomenon prevalent in medical images, and existing weakly-supervised segmentation methods fall short in refining class activation maps without fully exploiting SAM’s capabilities. To tackle this, the study proposes a SAM-based weakly-supervised framework named WeakMedSAM. WeakMedSAM includes two key components: the Sub-Class Exploration (SCE) module and the Prompt Affinity Mining (PAM) module. The SCE module explicitly learns intra-class representations by dividing a main category into multiple subcategories, mitigating interference from co-occurrence. The PAM module leverages SAM’s prompting ability to capture affinity, effectively integrating structural information and refining class activation maps without additional training or parameter overhead. Extensive evaluation on three benchmark datasets shows WeakMedSAM significantly outperforms existing weakly-supervised segmentation methods.
Related Paper:
Key Achievement 3: Adaptively Collaborative Training Framework for Foundation and Conventional Models
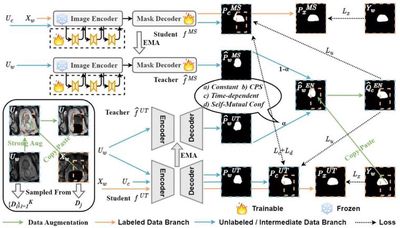
Foundational segmentation models exhibit remarkable zero-shot generalization across various medical segmentation tasks and can be transferred to different downstream domains to enhance performance. However, in scenarios with limited annotations and domain shifts, fine-tuning often faces challenges of high-confidence mispredictions that are hard to self-correct, leading to cumulative bias. This study introduces a collaborative training paradigm guided by conventional models, enabling the foundation model to obtain more reliable pseudo-labels during self-training. Its core mechanisms include: (1) the Self-Mutual Confidence (SMC) dynamic evaluation module, which adaptively adjusts the dominance between the foundation and conventional models at different training stages—leveraging the conventional model’s robustness to improve pseudo-label quality while avoiding early overfitting on limited annotations; and (2) the Consensus-Divergence Consistency Regularization (CDCR), which enforces consensus-divergence constraints to strengthen collaborative representation learning between the two models. Experimental results show the proposed approach outperforms existing methods on four public datasets.
Related Paper: