Team Members
Research Overview
The LLM + Knowledge research group has published more than 20 papers in high-level international conferences and journals in the fields of artificial intelligence, knowledge graphs, and natural language processing. It has undertaken over 10 related R&D projects for companies such as Huawei, Tencent, BAAI, Baichuan, State Grid, and CETC.
Representative Achievement 1: Efficient Collaboration Between Language Models and Graph Models
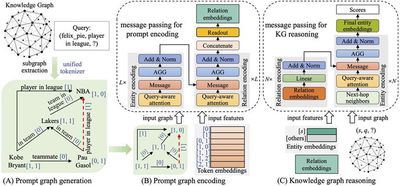
Large Language Models (LLMs) face challenges such as knowledge gaps and difficulty in updating internal knowledge, often leading to the problem of “hallucinations”. Knowledge graphs, which store vast amounts of structured knowledge, provide a data foundation for addressing this issue. In recent years, our research team has conducted in-depth studies following the “foundation model - knowledge injection - retrieval augmentation” framework and has published a series of findings in top-tier international conferences: At NeurIPS 2024, we proposed the first knowledge graph foundation model in China; At NAACL 2024, we presented an LLM enhancement method based on embedding-based knowledge adapters and instruction tuning; At NAACL 2025, we introduced a retrieval-augmented generation (RAG) method for question answering (QA) using knowledge graphs.
Related Paper:
Representative Achievement 2: Large Model Controllable Generation
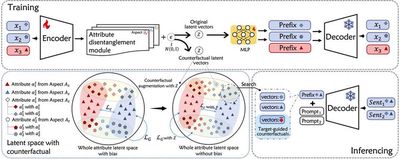
With the rapid development of large models, ensuring controllability over the attributes of generated content is crucial. This includes the ability to regulate aspects such as sentiment tendencies and topic types. Our research team has made several advancements in this area: At ACL 2024, we investigated the issue of imbalanced attribute associations and introduced disentangled counterfactual augmentation; At AAAI 2024, we explored optimization strategies and proposed a multi-list preference optimization strategy for fine-tuning protein large models; At ICDE 2024, we studied model interpretability by integrating knowledge graphs and designed a semantic matching-based explanation generation method.
Related Paper:
Representative Achievement 3: Domain-specific Large Models
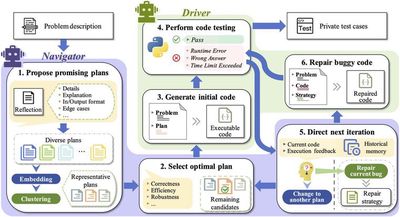
The construction of domain-specific large models is crucial for enhancing the intelligence level of specific industries. Compared to general-purpose large models, domain-specific models can more accurately comprehend specialized knowledge, provide high-quality decision support, and improve the reliability and interpretability of real-world applications. In medicine, our research team developed the “ChaoYi” large model, which enables personalized health education and prescription generation for chronic diseases such as diabetes and hypertension. It serves 20 primary healthcare centers in Shanghai and Nanjing. In software engineering, we developed a code large model to assist with code generation and optimization, exploring cutting-edge advancements in intelligent software development.