Large Model Learning Algorithms and Platform Research Group
Team Members
Research Overview
The high costs (GPU hardware, electricity, etc.) have become a major hurdle for the sustainable development of artificial intelligence, especially for large models. Nanjing University’s School of Computer Science has developed efficient training and inference algorithms that accelerate large model processes through algorithm innovation, reducing costs or enabling the training of larger, more accurate models with the same resources. Furthermore, by integrating these innovations, they have built a training and inference system and platform that supports high accuracy with low-cost deployment. Representative achievements include:
Achievement 1: Efficient Distributed Training Algorithms and Platform
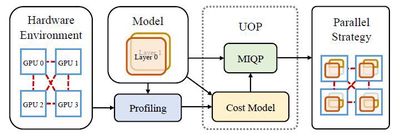
Training large models often requires multi-machine, multi-GPU distributed training. Distributed training poses significant challenges—in our experiments, 64%–87% of runs fail due to suboptimal hyperparameter setups (e.g., model partitioning, data distribution). Moreover, when training is slow, many only consider scaling hardware, overlooking the impact of distributed training algorithms that can significantly boost computational efficiency, often several times or even dozens of times faster. We propose a series of efficient algorithms—including communication optimization, asynchronous methods, fault tolerance, and automatic parallelism—and developed UniAP, the first platform to jointly optimize intra-layer and inter-layer parallel strategies. Given a model and hardware configuration, UniAP can automatically search for the optimal distributed training strategy, achieving speedups of up to 9x under certain conditions, while addressing issues due to improper hyperparameter settings. UniAP has also been adapted to domestic AI hardware.
Related Papers:
- Hao Lin, Ke Wu, Jie Li, Jun Li, Wu-Jun Li. UniAP: Unifying Inter- and Intra-Layer Automatic Parallelism by Mixed Integer Quadratic Programming. CVPR 2025.
- Shen-Yi Zhao, Chang-Wei Shi, Yin-Peng Xie, Wu-Jun Li. Stochastic Normalized Gradient Descent with Momentum for Large-Batch Training. SCIENCE CHINA Information Sciences (SCIS), 2024.
- Chang-Wei Shi, Yi-Rui Yang, Wu-Jun Li. Ordered Momentum for Asynchronous SGD. Advances in Neural Information Processing Systems (NeurIPS), 2024.
- Yi-Rui Yang, Chang-Wei Shi, Wu-Jun Li. On the Effect of Batch Size in Byzantine-Robust Distributed Learning. The Twelfth International Conference on Learning Representations (ICLR), 2024.
- Chang-Wei Shi, Shen-Yi Zhao, Yin-Peng Xie, Hao Gao, Wu-Jun Li. Global Momentum Compression for Sparse Communication in Distributed SGD. arXiv 2024.
Achievement 2: Efficient Training Algorithms Based on Continual Learning
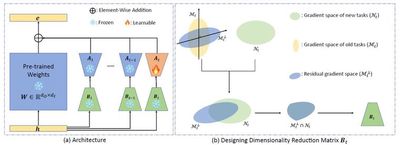
Continual learning aims to enable models to constantly learn new tasks while retaining previous knowledge, which is crucial for efficiently training large models. Typically, training large models requires massive GPU clusters and huge datasets, incurring high costs. With continual learning, new versions of large models can be incrementally built on previous ones without re-accessing all historical data, substantially reducing training overhead. However, existing large models often suffer from “catastrophic forgetting” where new task training compromises previous performance. To overcome this, models must balance stability (retaining old skills) and plasticity (learning new tasks). We propose InfLoRA, a novel method that injects a low-rank branch into pre-trained weights; our theoretical analysis shows that fine-tuning the low-rank branch is equivalent to adjusting weights within a subspace spanned by the low-rank matrices. This carefully designed subspace avoids interfering with previous knowledge, striking an effective balance to improve overall model accuracy. InfLoRA is the first approach to bridge LoRA-based tuning with full-parameter fine-tuning for overcoming forgetting.
Related Papers:
- Yan-Shuo Liang, Wu-Jun Li, InfLoRA: Interference-Free Low-Rank Adaptation for Continual Learning, CVPR 2024.
Achievement 3: Efficient Inference Algorithms and Platform
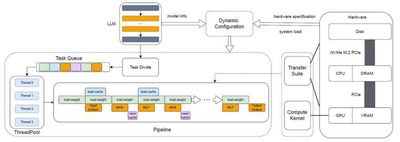
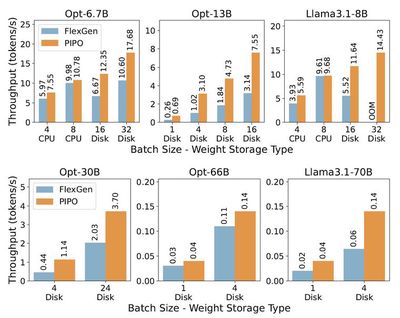
As large models evolve, the demand for inference and deployment hardware rises sharply. To address this, we innovated in both model compression and system architecture to design an efficient inference algorithm and platform. In terms of compression, our LCQ (Low-rank Codebook Quantization) allows the quantization dictionary to have a rank greater than one—reducing quantization loss compared to traditional approaches with a rank of one. Regarding system architecture, our offloading method stores parts of the model in CPU memory or on disk, enabling the inference of models that exceed the GPU’s memory capacity. Existing offloading frameworks (like FlexGen) suffer from low concurrency and suboptimal disk utilization, leading to poor GPU usage. Our novel Pipelined Offloading (PIPO) framework automatically determines the optimal offloading strategy based on model and hardware specifications, complemented by data transfer optimizations and custom CUDA kernel modifications to boost inference throughput. Experiments show that while conventional methods reach less than 40% GPU utilization, PIPO can push it above 90%, with inference speeds up to 3.1 times faster.
Related Papers:
- Wen-Pu Cai, Ming-Yang Li, Wu-Jun Li, LCQ: Low-Rank Codebook based Quantization for Large Language Models, arXiv 2024.


- Yangyijian Liu, Jun Li, Wu-Jun Li, PIPO: Pipelined Offloading for Efficient Inference on Consumer Devices, in arXiv, 2025.