Embodied Decision Large Model Research Group
Team Members
Overview of Key Achievements
The Embodied Decision Large Model Research Group focuses on cutting-edge research in embodied intelligence. Our research aims to build a generalizable embodied agent with investigations in embodied representation learning, policy learning, and hierarchical planning and execution. Below are some representative achievements:
Representative Achievement 1: STP – A Spatiotemporal Predictive Visual Representation Pre-training Model for Robotic Motor Control
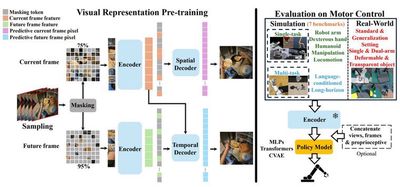
This work leverages a large-scale human first-person manipulation video dataset and employs decoupled spatial and temporal predictions as self-supervised proxy tasks to propose the image representation model STP dedicated for robotic motion control. The pre-trained STP model can be directly transferred to various robotic control tasks without fine-tuning and has outperformed existing baselines in over 50 tasks across real and seven simulated environments. These tasks include operations of single robotic arms, dual robotic arms, three-fingered dexterous hands, five-fingered dexterous hands, as well as humanoid robots.
Related papers:
Jiange Yang, Bei Liu, Jianlong Fu, Bocheng Pan, Gangshan Wu, Limin Wang, Spatiotemporal Predictive Pre-training for Robotic Motor Control.
Representative Achievement 2: SPA – A 3D Rendering Driven Visual Representation Pre-training Model for Embodied Intelligence
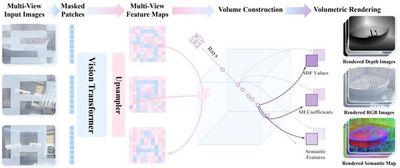
In this work, we propose a visual representation learning framework, SPA, which enhances 3D spatial awareness to improve representation learning in embodied intelligence tasks. SPA constructs a large-scale multi-view dataset with camera poses, depth maps, and semantic feature annotations by synthesizing indoor scenes and real-world robot interaction scenarios. It then builds 3D volumetric features from multi-view images and camera poses, and uses masking techniques along with differentiable neural rendering to generate RGB images, depth maps, and semantic maps. Additionally, Eikonal regularization and SDF supervision further improve 3D geometric consistency. Trained for 6000 GPU hours, SPA achieves superior average performance over other baseline methods across more than 200 tasks in both real environments and eight simulated settings, ranking first in up to 30.3% of the tasks.
Related papers:
Haoyi Zhu, Honghui Yang, Yating Wang, Jiange Yang, Limin Wang, Tong He, SPA: 3D Spatial-Awareness Enables Effective Embodied Representation, in ICLR 2025.
Representative Achievement 3: Tra-MoE – An Embodied Trajectory Prediction and Decision Model Driven by Multi-domain Data Learning
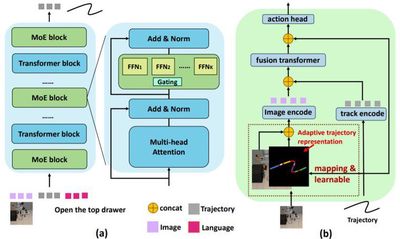
This work introduces Tra-MoE, a trajectory prediction model based on a sparsely gated mixture-of-experts architecture. By balancing parameter collaboration and specialization, Tra-MoE learns a more generalizable trajectory prediction model from large-scale, multi-domain, unlabeled video data, surpassing dense baselines of equivalent parameter scale. It effectively integrates simulation videos rendered by diverse physics engines with real-world manipulation videos involving humans, single robotic arms, and dual robotic arms. Furthermore, the work proposes an adaptive policy-conditioning method that leverages predicted trajectories to guide robotic policies, significantly enhancing downstream performance.
Related papers:
Jiange Yang, Haoyi Zhu, Yating Wang, Gangshan Wu, Tong He, Limin Wang, Learning Trajectory Prediction Model from Multiple Domains for Adaptive Policy Conditioning, in CVPR 2025.
Representative Achievement 4: A Generalizable Hierarchical Planning and Execution Framework and System
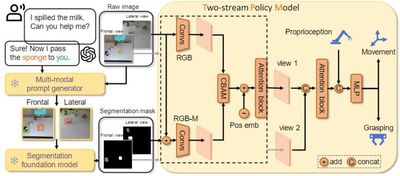
Although vision-language models trained on internet-scale data achieve impressive generalization across various tasks, their inability to interact with the real world limits their physical understanding. Conversely, robotic policies trained via imitation learning capture skills from human demonstrations; however, high data collection costs and homogenization hinder robust generalization. This work integrates a masked modality from language reasoning into an end-to-end policy model to enable sample-efficient generalization in robotic manipulation. By fusing semantic, geometric, and temporal priors inherent in internet foundational models with the diversity captured through imitation learning, the proposed approach bridges perception, reasoning, planning, and decision-making. It has been cited by teams from Stanford (Fei-Fei Li) and UC Berkeley (Jitendra Malik), and its hierarchical scheme is also adopted by leading embodied intelligence companies like Figure AI and Physical Intelligence.
Related papers:
Jiange Yang, Wenhui Tan, Chuhao Jin, Keling Yao, Bei Liu, Jianlong Fu, Ruihua Song, Gangshan Wu, Limin Wang, Transferring Foundation Models for Generalizable Robotic Manipulation, in WACV 2025 Oral.