Team Members
Research Overview
The Controlled Generation Research Group has long been engaged in research related to the generation capabilities of large language models and multimodal models. Currently, the group focuses on controllable generation techniques for large models to enhance their outputs along specific attributes. Their research centers on methods such as intervention and guidance of large models, conditional control in multimodal large models, and neuron or activation localization within large models to steer their generation. Some representative achievements are as follows:
Achievement 1: Controllable Generation Based on Language Model Steering
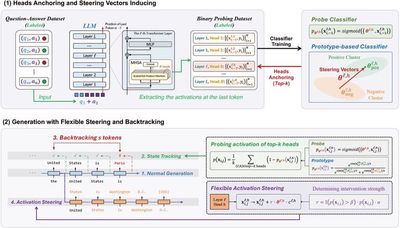
Large language model steering techniques have attracted widespread attention due to their ability to directly modify output activations without fine-tuning the model. Previous methods often fail to determine whether intervention is needed, accurately estimate intervention strength, and dynamically decide the timing of intervention. To address this, our work proposes a flexible activation steering technique that flexibly determines the strength and timing of intervention by tracking the degree of deviation in generated content at each step of generation. We further propose a backtracking mechanism to guide already deviated content back to the correct direction.
Related Papers:
Achievement 2: Representation Generation Techniques for Large Models Based on Model Intervention
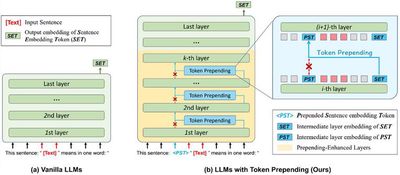
Extracting sentence embeddings from large language models has attracted widespread attention due to requiring no data or fine-tuning. Previous methods typically rely on prompting to elicit the model’s ability to encode sentence embeddings. However, such methods are limited by the unidirectional attention mechanism of large language models and fail to effectively capture the core semantics of sentences. To address this, (1) the research group proposes a token prepending approach to overcome the limitations of the unidirectional attention of large language models. (2) The research group proposes a contrastive prompting approach by introducing auxiliary prompts and inference-time steering to encode the core semantics of sentences.
Related Papers:
Zifeng Cheng, Zhonghui Wang, Yuchen Fu, Zhiwei Jiang, Yafeng Yin, Cong Wang, Qing Gu. Contrastive Prompting Enhances Sentence Embeddings in LLMs through Inference-Time Steering, in ACL 2025.
Achievement 3: Generation Techniques Based on Multimodal Large Models
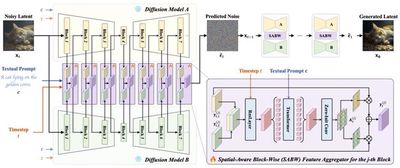
With the rapid development of visual generation techniques, enhancing or controlling generated content has become increasingly important. (1) To improve the generalization of automatic prompts across different diffusion models, the research group proposes the AP-Adapter two-stage approach. In the first stage, AP-Adapter uses LLM to optimize automatic keyword prompts for natural language descriptions; in the second stage, the approach harmonizes feature differences across models through domain prototype representation enhancement, enabling prompt generation to adapt to unseen models. (2) To dynamically integrate the capabilities of multiple diffusion models and fully leverage their advantages, the research group proposes the AFA method. AFA dynamically adjusts the feature contributions of different models by designing lightweight spatial-aware block-level feature aggregators, achieving dynamic feature fusion at the feature level. (3) To address the imbalance of multimodal control signal weights in audio-driven portrait video generation, the research group proposes V-Express. This approach introduces conditional dropout operations and progressive training strategies, enabling weak control signals to be effectively utilized and work synergistically with strong control signals. (4) To address the limitation that existing sign language video generation methods rely on single coarse-grained conditions, the research group proposes SignViP. This approach effectively improves the naturalness and semantic expressiveness of generated videos through discretizing multi-fine-grained conditions, combined with multi-condition token translation and joint training.
Related Papers:
Yuchen Fu, Zhiwei Jiang, Yuliang Liu, Cong Wang, Zexuan Deng, Zhaoling Chen, Qing Gu. AP-Adapter: Improving Generalization of Automatic Prompts on Unseen Text-to-Image Diffusion Models, in NeurIPS 2024.
Cong Wang, Kuan Tian, Yonghang Guan, Fei Shen, Zhiwei Jiang, Qing Gu, Jun Zhang. Ensembling Diffusion Models via Adaptive Feature Aggregation, in ICLR 2025.
Cong Wang, Kuan Tian, Jun Zhang, Yonghang Guan, Feng Luo, Fei Shen, Zhiwei Jiang, Qing Gu, Xiao Han, Wei Yang. V-Express: Conditional Dropout for Progressive Training of Portrait Video Generation, in arXiv:2406.02511.