Cloud Large Model System Research Group
Team Members
Key Achievements
The Cloud Large Model System Research Group is dedicated to exploring system-level performance optimization technologies for large model training, inference, and deployment in cloud environments. The team’s key research directions include: storage management optimization for cloud-based large models, efficient distribution and loading mechanisms, training process optimization strategies, and inference performance optimization technologies. While conducting cutting-edge academic research, the team maintains deep industry-academia collaboration with leading enterprises such as Alibaba Cloud, Huawei, Ant Group, and Xiaohongshu, promoting the practical application of research results in industry and open-source community development. In undergraduate/graduate education, the team offers specialized courses on large model inference system kernel principles and optimization techniques (pilot teaching phase, internal invitation), systematically cultivating students’ deep understanding of large model inference processes and practical advanced optimization capabilities. The following showcases some of the team’s representative research achievements:
Achievement 1: Hotness-Aware KV Cache Offloading and Prefetching Scheduling Optimization for Large Model Inference Systems
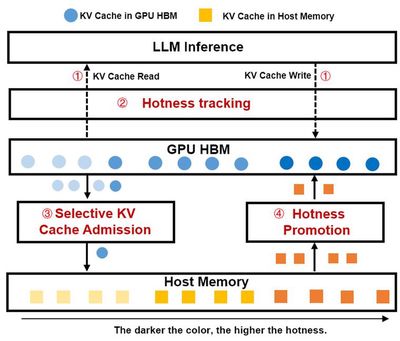
As Large Language Models (LLMs) demonstrate exceptional performance in multi-task scenarios, prompt engineering techniques (such as Few-Shot Learning, Chain-of-Thought, RAG) have become core methods for optimizing model outputs. However, such methods typically rely on structured prompts containing large amounts of shared prefixes (such as system instructions, templates, retrieved documents), leading to redundant KV Cache storage during inference, significantly increasing GPU memory usage and limiting system concurrency and throughput. Although existing systems (such as vLLM, SGLang) have attempted to optimize memory efficiency through KV Cache prefix sharing, two key challenges remain: (1) Insufficient dynamic hotness tracking - existing methods struggle to accurately quantify hotness changes in prefix KV Cache; (2) Inefficient heterogeneous storage coordination: lack of efficient collaborative scheduling mechanisms between CPU memory and GPU memory. This work addresses the high KV Cache memory usage and large multi-level storage transfer overhead in large model inference systems under long prompt prefix sharing scenarios, proposing HotPrefix - an efficient KV Cache management and scheduling framework for long prompt prefix sharing scenarios. Its core innovations include: (1) Lightweight hotness-aware mechanism: achieving fine-grained KV Cache access pattern tracking through dynamic construction of prefix tree node hotness models; (2) Heterogeneous storage collaborative scheduling: selectively offloading low-frequency accessed KV Cache to host memory and preloading high-hotness prefixes to GPU memory through asynchronous pipelines; (3) Computation-storage joint optimization: maximizing reuse of computed KV Cache, reducing prefill phase computational overhead, and improving memory hit rates. HotPrefix can significantly improve end-to-end inference latency and throughput in shared prefix scenarios, reducing inference latency by up to 2x and 2.25x compared to SGLang and vLLM respectively, applicable to LLM inference long prompts and RAG application services.
Related Paper:
Yuhang Li, Rong Gu, Chengying Huan, Zhibin Wang, Renjie Yao, Chen Tian, Guihai Chen. HotPrefix: Hotness-Aware KV Cache Scheduling for Efficient Prefix Sharing in LLM Inference Systems, accepted, to appear in SIGMOD 2026. (CCF-A, Nanjing University is the sole completing institution)
Achievement 2: Dataset Abstraction and Elastic Cache Orchestration System for Cloud-Native Deep Learning Training Jobs
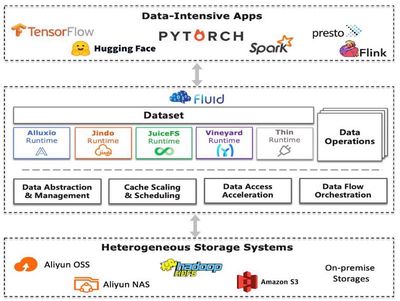
In recent years, deep learning technologies represented by large models have achieved breakthrough progress in text understanding, multimodal perception, and other fields. However, the compute-intensive and data-intensive characteristics of deep learning make it highly dependent on high-performance computing clusters and massive training data. To meet elastic resource demands, cloud-native technologies have gradually become the mainstream choice for deep learning training, but their compute-storage separation architecture introduces significant data I/O bottlenecks, specifically manifested in low data access efficiency, difficult dynamic resource adaptation, and weak cache sharing capabilities. This paper proposes Fluid - a data abstraction and elastic cache orchestration system for cloud-native deep learning training, with core contributions including: (1) Unified data abstraction layer: encapsulating distributed data sources through declarative datasets (Dataset CRD), achieving user-transparent data access optimization; (2) Dynamic cache elastic scaling: based on real-time training speed monitoring (Throughput-Aware Autoscaling), dynamically adjusting cache resource quotas to alleviate data access performance bottlenecks; (3) Global cache-aware scheduling: building dataset hotness models and cache topology awareness mechanisms, reusing cached data across jobs to improve cluster-level data locality. Experiments prove that the system can achieve approximately 3x and 2x performance improvements in single-job and multi-job scenarios respectively. Fluid has evolved from an initial academic system prototype through deep collaboration with major companies like Alibaba Cloud and Alluxio into an official open-source project of the international Cloud Native Computing Foundation (Professor Gu Rong serves as Fluid open-source community chair, with multiple lab students growing into Fluid open-source project Committers and joining major companies). Open-source users include more than 10 industry-leading enterprises such as Alibaba Cloud, Baidu Cloud, China Telecom Cloud, 360 Company, Xiaomi, OPPO, and Weibo. It was rated as a 2021 China Academy of Information and Communications Technology OSCAR Peak Open Source Project and won the first prize in the 2022 China Open Source Innovation Competition.
Related Papers:
Rong Gu, Kai Zhang, Zhihao Xu, Yang Che, Bin Fan, Haojun Hou, Haipeng Dai, Li Yi, Yu Ding, Guihai Chen, Yihua Huang. Fluid: Dataset Abstraction and Elastic Acceleration for Cloud-native Deep Learning Training Jobs, in ICDE 2022. (CCF-A, Nanjing University is the leading completing institution)
Rong Gu, Zhihao Xu, Yang Che, Xu Wang, Haipeng Dai, Kai Zhang, Bin Fan, Haojun Hou, Li Yi, Yu Ding, Yihua Huang, Guihai Chen. High-level Data Abstraction and Elastic Data Caching for Data-intensive AI Applications on Cloud-native Platforms, in IEEE TPDS 2023. (CCF-A, Nanjing University is the leading completing institution)
Fluid Open Source Project and Community Links: